Linear Neuron
A Linear Neuron is an artificial neuron that uses a Linear Activation Function.
- AKA: Linear Activation Unit.
- Context:
- It can be mathematically described as
[math]\displaystyle{ y_j=f(z_j)=a_1z_j+a_0\quad \text{with} \quad z_j=\sum_{i=0}^nw_{ji}x_i+b \quad \text{for}\quad j=0,\cdots, p }[/math]
where [math]\displaystyle{ x_i }[/math] are the Neural Network Input vector, [math]\displaystyle{ y_j }[/math] are the Neural Network Output vector, [math]\displaystyle{ w_{ji} }[/math] is the Neural Network Weights and [math]\displaystyle{ b }[/math] is the Bias Neuron, [math]\displaystyle{ a_0 }[/math] and [math]\displaystyle{ a_1 }[/math] are constant.
- It ranges from being an Identity Neuron to being a Parametric Linear Neuron.
- It can be mathematically described as
- Example(s):
- Counter-Example(s):
- See: Artificial Neural Network, Perceptron.
References
2017
- (Mate Labs, 2017) ⇒ Mate Labs Aug 23, 2017. Secret Sauce behind the beauty of Deep Learning: Beginners guide to Activation Functions
- QUOTE: Identity or Linear activation function is the simplest activation function of all. It applies identity operation on your data and output data is proportional to the input data. Problem with linear activation function is that it’s derivative is a constant and it’s gradient will be a constant too and the descent will be on a constant gradient.
[math]\displaystyle{ f(x)=x }[/math]
Range: [math]\displaystyle{ (-\infty, +\infty) }[/math]
Examples: [math]\displaystyle{ f(2) = 2 }[/math] or [math]\displaystyle{ f(-4) = -4 }[/math]
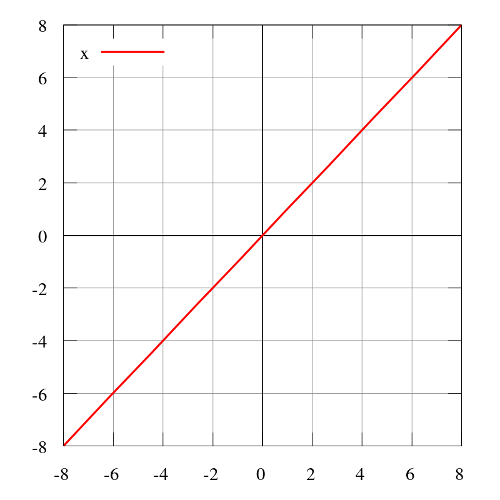
- QUOTE: Identity or Linear activation function is the simplest activation function of all. It applies identity operation on your data and output data is proportional to the input data. Problem with linear activation function is that it’s derivative is a constant and it’s gradient will be a constant too and the descent will be on a constant gradient.
.