Neuron Activation Function
A Neuron Activation Function is an decision function in an artificial neuron.
- AKA: Artificial Neural Network Transfer Function.
- Context:
- It can be a numeric-input binary-output function that is used for a classification process.
- It can range from being a Symmetric Activation Function to being an Asymmetric Activation Function.
- It can range from being a Step Activation Function to being a Linear Activation Function to being a Nonlinear Activation Function.
- Example(s):
- a Step Function-based Activation Function, e.g. [math]\displaystyle{ \varphi(v) = \begin{cases} a: \ \text{if} \ v \gt c \\ b: \ \text{if} \ v \ge c\end{cases} }[/math];
- a Ramp Function-based Activation Function, e.g. [math]\displaystyle{ \varphi(v) = \begin{cases} a: \ \text{if} \ v \gt c \\ b: \ \text{if} \ v \ge d \\ a+((v-c)(b-a)/(d-c)): \ \text{otherwise} \end{cases} }[/math];
- a Rectified-based Activation Function , in a ReLU neuron, using in a rectifier linear unit-based neural net, such as:
- a Clipped Rectifier Unit Activation Function,
- a Concatenated Rectified Linear Activation Function,
- an Exponential Linear Activation Function,
- a Leaky Rectified Linear Activation Function,
- a Noisy Rectified Linear Activation Function,
- a Parametric Rectified Linear Activation Function,
- a Randomized Leaky Rectified Linear Activation Function,
- a Scaled Exponential Linear Activation Function,
- a Softplus Activation Function,
- a S-shaped Rectified Linear Activation Function;
- a Logistic Sigmoid-based Activation Function, in logistic sigmoid neurons, used in logistic-based neural nets, such as:
- a Hyperbolic Tangent-based Activation Function ,in hyperbolic tangent neurons, used in hyperbolic tangent-based neural net, such as:
- a Gaussian-based Activation Function, in a Gaussian neuron, using in a Gaussian-based neural net, e.g. [math]\displaystyle{ \varphi(v) = \frac{1}{\sqrt{2 \pi} \sigma} \operatorname{exp} \Bigl( -1/2 (\frac{v- \mu}{\sigma})^2 \Bigr) }[/math];
- a Softmax-based Activation Function such as:
- a Softsign Activation Function;
- a Softshrink Activation Function;
- a Adaptive Piecewise Linear Activation Function;
- a Bent Identity Activation Function;
- a Maxout Activation Function;
- a Long Short-Term Memory Unit-based Activation Function such as:
- an Inverse Square Root Unit-based Activation Function;
- a SoftExponential Activation Function;
- a Sinusoid-based Activation Function.
- …
- Counter-Example(s):
- See: Artificial Neural Network, Artificial Neuron, Neural Network Topology, Neural Network Layer.
References
2018a
- (Ahirwar, 2017) ⇒ Kailash Ahirwar, https://buzzrobot.com/everything-you-need-to-know-about-neural-networks-6fcc7a15cb4 Retrieved: 2018-01-28.
- QUOTE: Activation Function(Transfer Function) — Activation functions are used to introduce non-linearity to neural networks. It squashes the values in a smaller range viz. a Sigmoid activation function squashes values between a range 0 to 1. There are many activation functions used in deep learning industry and ReLU, SeLU and TanH are preferred over sigmoid activation function. In this article I have explained different activation functions available.

- QUOTE: Activation Function(Transfer Function) — Activation functions are used to introduce non-linearity to neural networks. It squashes the values in a smaller range viz. a Sigmoid activation function squashes values between a range 0 to 1. There are many activation functions used in deep learning industry and ReLU, SeLU and TanH are preferred over sigmoid activation function. In this article I have explained different activation functions available.
2018b
- (Santos, 2018) ⇒ Santos (2018) "Activation Functions". In: Neural Networks - Artificial Inteligence Retrieved: 2018-01-28.
- QUOTE: After the neuron do the dot product between it's inputs and weights, it also apply a non-linearity on this result. This non-linear function is called Activation Function.
On the past the popular choice for activation functions were the sigmoid and tanh. Recently it was observed the ReLU layers has better response for deep neural networks, due to a problem called vanishing gradient. So you can consider using only ReLU neurons.
sigmoid: [math]\displaystyle{ \sigma(x)=\dfrac{1}{1+e^{−x}} }[/math]
tanh:[math]\displaystyle{ \sigma(x)=\dfrac{e^x−e^x}{e^x+e^x} }[/math]
ReLU:[math]\displaystyle{ \sigma(x)=max(0,x) }[/math]

- QUOTE: After the neuron do the dot product between it's inputs and weights, it also apply a non-linearity on this result. This non-linear function is called Activation Function.
2018c
- (CS231n, 2018) ⇒ Commonly used activation functions. In: CS231n Convolutional Neural Networks for Visual Recognition Retrieved: 2018-01-28.
- QUOTE: Every activation function (or non-linearity) takes a single number and performs a certain fixed mathematical operation on it. There are several activation functions you may encounter in practice:
- Sigmoid. The sigmoid non-linearity has the mathematical form [math]\displaystyle{ \sigma(x)=1/(1+e^{−x}) }[/math] and is shown in the image above on the left. As alluded to in the previous section, it takes a real-valued number and “squashes” it into range between 0 and 1. In particular, large negative numbers become 0 and large positive numbers become 1. The sigmoid function has seen frequent use historically since it has a nice interpretation as the firing rate of a neuron: from not firing at all (0) to fully-saturated firing at an assumed maximum frequency (1) (...)
- Tanh. The tanh non-linearity is shown on the image above on the right. It squashes a real-valued number to the range [-1, 1]. Like the sigmoid neuron, its activations saturate, but unlike the sigmoid neuron its output is zero-centered. Therefore, in practice the tanh non-linearity is always preferred to the sigmoid nonlinearity. Also note that the tanh neuron is simply a scaled sigmoid neuron, in particular the following holds: [math]\displaystyle{ tanh(x)=2\sigma(2x)−1 }[/math] (...)
- ReLU. The Rectified Linear Unit has become very popular in the last few years. It computes the function [math]\displaystyle{ f(x)=max(0,x) }[/math]. (...)
- Leaky ReLU. Leaky ReLUs are one attempt to fix the “dying ReLU” problem. Instead of the function being zero when [math]\displaystyle{ x \lt 0 }[/math], a leaky ReLU will instead have a small negative slope (of 0.01, or so). That is, the function computes [math]\displaystyle{ f(x)=1(x\lt 0)(αx)+1(x\gt =0)(x) }[/math] where [math]\displaystyle{ \alpha }[/math] is a small constant (...)
- Maxout. Other types of units have been proposed that do not have the functional form [math]\displaystyle{ f(w^Tx+b) }[/math] where a non-linearity is applied on the dot product between the weights and the data (...)
- QUOTE: Every activation function (or non-linearity) takes a single number and performs a certain fixed mathematical operation on it. There are several activation functions you may encounter in practice:
2018d
- (Wikipedia, 2018) ⇒ https://en.wikipedia.org/wiki/Activation_function Retrieved:2018-1-28.
- In computational networks, the activation function of a node defines the output of that node given an input or set of inputs. A standard computer chip circuit can be seen as a digital network of activation functions that can be "ON" (1) or "OFF" (0), depending on input. This is similar to the behavior of the linear perceptron in neural networks. However, only nonlinear activation functions allow such networks to compute nontrivial problems using only a small number of nodes. In artificial neural networks this function is also called the transfer function.
2018e
- (ML Glossary, 2018) ⇒ (2008). Accuracy. In: Machine Learning Glossary https://developers.google.com/machine-learning/glossary/ Retrieved 2018-04-22.
2011
- (Glorot et al., 2011) ⇒ Xavier Glorot, Antoine Bordes, and Yoshua Bengio. (2011). “Deep Sparse Rectifier Networks.” In: Proceedings of the 14th International Conference on Artificial Intelligence and Statistics
- ABSTRACT: While logistic sigmoid neurons are more biologically plausible than hyperbolic tangent neurons, the latter work better for training multi-layer neural networks.
- QUOTE: … The most commonly used activation functions in the deep learning and neural networks literature are the standard logistic sigmoid and the hyperbolic tangent (see Figure 1, right), which are equivalent up to a linear transformation. The hyperbolic tangent has a steady state at 0, and is therefore preferred from the optimization standpoint (LeCun et al., 1998; Bengio and Glorot, 2010), but it forces an antisymmetry around 0 which is absent in biological neurons.
- QUOTE: … An activation function is termed, respectively antisymmetric or symmetric when its response to the opposite of a strongly excitatory input pattern is respectively a strongly inhibitory or excitatory one, and one-sided when this response is zero.
2005
- (Golda,2005) ⇒ Adam Golda (2005). "Introduction to neural networks"
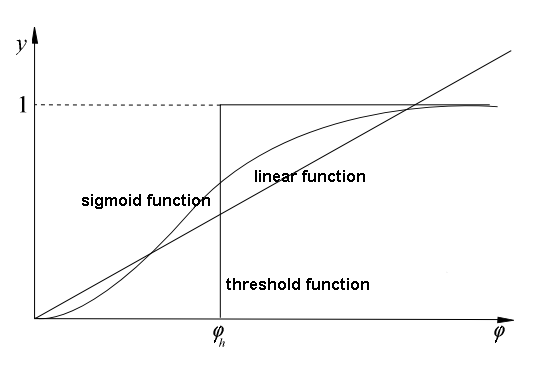
- QUOTE: In accordance with such model, the formula of the activation potential [math]\displaystyle{ \varphi }[/math] is as follows
[math]\displaystyle{ \varphi=\sum_{i=1}^P u_iw_i }[/math]
Signal [math]\displaystyle{ }[/math] is processed by activation function, which can take different shapes. If the function is linear the output signal can be described as:
[math]\displaystyle{ y=k\varphi }[/math]
Neural networks described by above formula are called linear neural networks.
The other type of activation function is threshold function:
[math]\displaystyle{ y_j=\begin{cases} 1, & \mbox{for } \varphi \gt \varphi_h \\0, & \mbox{for others}\end{cases} \text{with} }[/math]
where [math]\displaystyle{ \varphi_h }[/math] is a given constant threshold value.
Functions that more accurate describe the non-linear characteristic of the biological neuron activation function are:
sigmoid function:
[math]\displaystyle{ y=\dfrac{1}{1+\exp({-\beta\varphi})} }[/math]
where [math]\displaystyle{ \beta }[/math] is a parameter,
and hyperbolic tangent function:[math]\displaystyle{ y=tgh\left(\dfrac{\alpha\varphi}{2}\right)=\dfrac{1 - \exp({-\alpha\varphi})}{1+\exp({-\alpha\varphi})} }[/math] where [math]\displaystyle{ \alpha }[/math] is a parameter.
The next picture presents the graphs of particular activation functions:
- QUOTE: In accordance with such model, the formula of the activation potential [math]\displaystyle{ \varphi }[/math] is as follows
- a. linear function,
- b. threshold function,
- c. sigmoid function.
1986
- (Williams, 1986) ⇒ Ronald J. Williams. (1986). “The Logic of Activation Functions.” In: (Rumelhart & McClelland, 1986).
- QUOTE: The notion of logical computation, in some form or other, seems to provide a convenient language for describing the operation of many of the networks we seek to understand. Digital computers are built out such constituents as AND and OR gates. Feature-detecting neurons in biological sensory system are often idealized as signaling the presence or absence of their preferred features by becoming highly active or inactively, respectively. It seems a relatively simple extension of this concept to allow the activity of units in the network to range over some interval rather than over just two values; in this case the activity of a unit is regarded as signaling its degree of confidence that its preferred feature is present, rather than just the presence or absence of this feature. There are several ways one might attempt to formalize this degree-of-confidence notion. For example, if the activation values range over the closed unit interval [0,1], one might treat such an activation value as a conditional probability: alternatively, it might be viewed as a measure of truth in some unit-interval-valued logic, such as fuzzy logic (Zadeh, 1965).