Linear Activation Function
(Redirected from linear activation function)
Jump to navigation
Jump to search
A Linear Activation Function is a Neuron Activation Function that is a linear function.
- Example(s):
- Counter-Example(s):
- See: Artificial Neural Network, Artificial Neuron, Neural Network Topology, Neural Network Layer, Neural Network Adder Function, Neural Network Weight, Neural Network Input, Neural Network Output.
References
2018a
- (Ahirwar, 2017) ⇒ Kailash Ahirwar, https://buzzrobot.com/everything-you-need-to-know-about-neural-networks-6fcc7a15cb4 Retrieved: 2018-01-28.
- QUOTE: Activation Function(Transfer Function) — Activation functions are used to introduce non-linearity to neural networks. It squashes the values in a smaller range viz. a Sigmoid activation function squashes values between a range 0 to 1. There are many activation functions used in deep learning industry and ReLU, SeLU and TanH are preferred over sigmoid activation function.
2018b
- (Santos, 2018) ⇒ Santos (2018) "Activation Functions". In: Neural Networks - Artificial Inteligence Retrieved: 2018-01-28.
- QUOTE: After the neuron do the dot product between it's inputs and weights, it also apply a non-linearity on this result. This non-linear function is called Activation Function.
On the past the popular choice for activation functions were the sigmoid and tanh. Recently it was observed the ReLU layers has better response for deep neural networks, due to a problem called vanishing gradient. So you can consider using only ReLU neurons.
sigmoid: [math]\displaystyle{ \sigma(x)=\dfrac{1}{1+e^{−x}} }[/math]
tanh:[math]\displaystyle{ \sigma(x)=\dfrac{e^x−e^x}{e^x+e^x} }[/math]
ReLU:[math]\displaystyle{ \sigma(x)=max(0,x) }[/math]
- QUOTE: After the neuron do the dot product between it's inputs and weights, it also apply a non-linearity on this result. This non-linear function is called Activation Function.
2018c
- (CS231n, 2018) ⇒ Commonly used activation functions. In: CS231n Convolutional Neural Networks for Visual Recognition Retrieved: 2018-01-28.
- QUOTE: Every activation function (or non-linearity) takes a single number and performs a certain fixed mathematical operation on it. There are several activation functions you may encounter in practice:
- Sigmoid. The sigmoid non-linearity has the mathematical form [math]\displaystyle{ \sigma(x)=1/(1+e^{−x}) }[/math] and is shown in the image above on the left. As alluded to in the previous section, it takes a real-valued number and “squashes” it into range between 0 and 1. In particular, large negative numbers become 0 and large positive numbers become 1. The sigmoid function has seen frequent use historically since it has a nice interpretation as the firing rate of a neuron: from not firing at all (0) to fully-saturated firing at an assumed maximum frequency (1) (...)
- Tanh. The tanh non-linearity is shown on the image above on the right. It squashes a real-valued number to the range [-1, 1]. Like the sigmoid neuron, its activations saturate, but unlike the sigmoid neuron its output is zero-centered. Therefore, in practice the tanh non-linearity is always preferred to the sigmoid nonlinearity. Also note that the tanh neuron is simply a scaled sigmoid neuron, in particular the following holds: [math]\displaystyle{ tanh(x)=2\sigma(2x)−1 }[/math] (...)
- ReLU. The Rectified Linear Unit has become very popular in the last few years. It computes the function [math]\displaystyle{ f(x)=max(0,x) }[/math]. (...)
- Leaky ReLU. Leaky ReLUs are one attempt to fix the “dying ReLU” problem. Instead of the function being zero when [math]\displaystyle{ x \lt 0 }[/math], a leaky ReLU will instead have a small negative slope (of 0.01, or so). That is, the function computes [math]\displaystyle{ f(x)=1(x\lt 0)(αx)+1(x\gt =0)(x) }[/math] where [math]\displaystyle{ \alpha }[/math] is a small constant (...)
- Maxout. Other types of units have been proposed that do not have the functional form [math]\displaystyle{ f(w^Tx+b) }[/math] where a non-linearity is applied on the dot product between the weights and the data (...)
- QUOTE: Every activation function (or non-linearity) takes a single number and performs a certain fixed mathematical operation on it. There are several activation functions you may encounter in practice:
2018d
- (ML Glossary, 2018) ⇒ (2008). Accuracy. In: Machine Learning Glossary https://developers.google.com/machine-learning/glossary/ Retrieved 2018-04-22.
2005
- (Golda,2005) ⇒ Adam Golda (2005). "Introduction to neural networks"
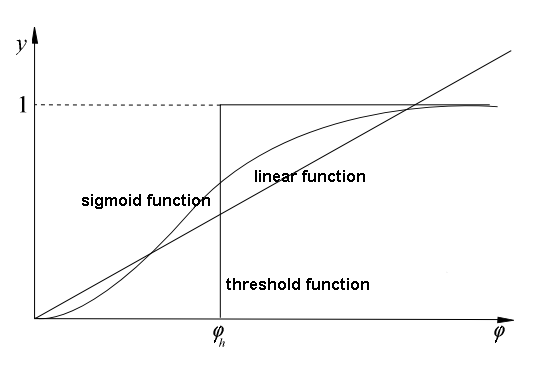
- QUOTE: The next picture presents the graphs of particular activation functions:
- a. linear function,
- b. threshold function,
- c. sigmoid function.