Rectified Linear Unit (ReLU) Activation Function
A Rectified Linear Unit (ReLU) Activation Function is a neuron activation function whose values on negative input are attenuated.
- AKA: ReLU Activation Function, Rectified Linear Activation Function.
- Context:
- It can (typically) be used in the activation of Rectified Linear Neurons.
- It can range from being a Simple RELU (an identity function after zero) to being a Complex RELU.
- Example(s):
torch.nn.ReLUa pytorch implementation,torch.nn.ReLU6a pytorch implementation,- a Clipped Rectifier Unit Activation Function,
- a Concatenated Rectified Linear Activation Function,
- an Exponential Linear Activation Function,
- a Leaky Rectified Linear Activation Function,
- a Noisy Rectified Linear Activation Function,
- a Parametric Rectified Linear Activation Function,
- a Randomized Leaky Rectified Linear Activation Function,
- a Scaled Exponential Linear Activation Function,
- a Softplus Activation Function,
- an S-shaped Rectified Linear Activation Function,
- …
- Counter-Example(s):
- a Heaviside Step Activation Function,
- a Ramp Function-based Activation Function,
- a Logistic Sigmoid-based Activation Function, such as: a Log-Sigmoid Activation Function,
- a Hyperbolic Tangent-based Activation Function, such as: a HardTanh Activation Function, or a Tanhshrink Activation Function,
- a Gaussian-based Activation Function,
- a Softmax-based Activation Function, such as: a LogSoftmax Activation Function, or a Softmin Activation Function,
- a Softsign Activation Function,
- a Softshrink Activation Function,
- a Adaptive Piecewise Linear Activation Function,
- a Bent Identity Activation Function,
- a Maxout Activation Function.
- See: Artificial Neural Network, Artificial Neuron, Neural Network Topology, Neural Network Layer, Neural Network Learning Rate.
References
2018a
- (Pyttorch, 2018) ⇒ http://pytorch.org/docs/master/nn.html#relu
- QUOTE:
class torch.nn.ReLU(inplace=False)sourceAApplies the rectified linear unit function element-wise [math]\displaystyle{ ReLU(x)=max(0,x) }[/math]
Parameters: inplace – can optionally do the operation in-place. Default: False
Shape:
*** Input: [math]\displaystyle{ (N,∗) }[/math] where * means, any number of additional dimensions
- Output: [math]\displaystyle{ (N,∗) }[/math], same shape as the input
- QUOTE:
- Examples:
>>> m = nn.ReLU() >>> input = autograd.Variable(torch.randn(2)) >>> print(input) >>> print(m(input))
2018b
- (Wikipedia, 2018) ⇒ https://en.wikipedia.org/wiki/Rectifier_(neural_networks) Retrieved:2018-2-4.
- In the context of artificial neural networks, the rectifier is an activation function defined as the positive part of its argument: [math]\displaystyle{ f(x) = x^+ = \max(0, x) }[/math] ,
where x is the input to a neuron. This is also known as a ramp function and is analogous to half-wave rectification in electrical engineering.
This activation function was first introduced to a dynamical network by Hahnloser et al. in a 2000 paper in Nature[1] with strong biological motivations and mathematical justifications.[2] . It has been demonstrated for the first time in 2011 to enable better training of deeper networks [3] , compared to the widely used activation functions prior to 2011, i.e., the logistic sigmoid (which is inspired by probability theory; see logistic regression) and its more practical counterpart, the hyperbolic tangent. The rectifier is,, the most popular activation function for deep neural networks. A unit employing the rectifier is also called a rectified linear unit (ReLU).[4] A smooth approximation to the rectifier is the analytic function : [math]\displaystyle{ f(x) = \log(1 + \exp x), }[/math] which is called the softplus function. [5] The derivative of softplus is [math]\displaystyle{ f'(x) = \exp x / (1 + \exp x) = 1 / (1 + \exp (-x)) }[/math] , i.e. the logistic function. Rectified linear units find applications in computer vision and speech recognition[6] [7] using deep neural nets.
- In the context of artificial neural networks, the rectifier is an activation function defined as the positive part of its argument: [math]\displaystyle{ f(x) = x^+ = \max(0, x) }[/math] ,
2018c
- (Santos, 2018) ⇒ Santos (2018) "Activation Functions". In: Neural Networks - Artificial Intelligence Retrieved: 2018-01-28.
- QUOTE: After the neuron do the dot product between it's inputs and weights, it also apply a non-linearity on this result. This non-linear function is called Activation Function.
On the past the popular choice for activation functions were the sigmoid and tanh. Recently it was observed the ReLU layers has better response for deep neural networks, due to a problem called vanishing gradient. So you can consider using only ReLU neurons.
sigmoid: [math]\displaystyle{ \sigma(x)=\dfrac{1}{1+e^{−x}} }[/math]
tanh:[math]\displaystyle{ \sigma(x)=\dfrac{e^x−e^x}{e^x+e^x} }[/math]
ReLU:[math]\displaystyle{ \sigma(x)=max(0,x) }[/math]
- QUOTE: After the neuron do the dot product between it's inputs and weights, it also apply a non-linearity on this result. This non-linear function is called Activation Function.
2018d
- (CS231n, 2018) ⇒ Commonly used activation functions. In: CS231n Convolutional Neural Networks for Visual Recognition Retrieved: 2018-01-28.
- QUOTE:
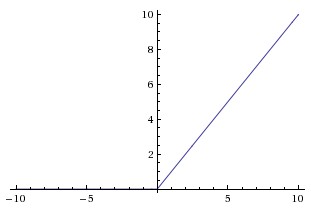
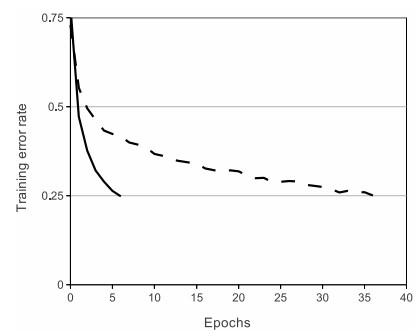 Left: Rectified Linear Unit (ReLU) activation function, which is zero when x < 0 and then linear with slope 1 when x > 0. Right: A plot from Krizhevsky et al. paper indicating the 6x improvement in convergence with the ReLU unit compared to the tanh unit.
Left: Rectified Linear Unit (ReLU) activation function, which is zero when x < 0 and then linear with slope 1 when x > 0. Right: A plot from Krizhevsky et al. paper indicating the 6x improvement in convergence with the ReLU unit compared to the tanh unit.ReLU. The Rectified Linear Unit has become very popular in the last few years. It computes the function [math]\displaystyle{ f(x)=max(0,x) }[/math]. In other words, the activation is simply thresholded at zero (see image above on the left). There are several pros and cons to using the ReLUs:
- (+) It was found to greatly accelerate (e.g. a factor of 6 in Krizhevsky et al.) the convergence of stochastic gradient descent compared to the sigmoid/tanh functions. It is argued that this is due to its linear, non-saturating form.
- (+) Compared to tanh/sigmoid neurons that involve expensive operations (exponentials, etc.), the ReLU can be implemented by simply thresholding a matrix of activations at zero.
- (-) Unfortunately, ReLU units can be fragile during training and can “die”. For example, a large gradient flowing through a ReLU neuron could cause the weights to update in such a way that the neuron will never activate on any datapoint again. If this happens, then the gradient flowing through the unit will forever be zero from that point on. That is, the ReLU units can irreversibly die during training since they can get knocked off the data manifold. For example, you may find that as much as 40% of your network can be “dead” (i.e. neurons that never activate across the entire training dataset) if the learning rate is set too high. With a proper setting of the learning rate this is less frequently an issue.
- QUOTE:
2017a
- (Mate Labs, 2017) ⇒ Mate Labs Aug 23, 2017. Secret Sauce behind the beauty of Deep Learning: Beginners guide to Activation Functions
- QUOTE: It trains 6 times faster than tanh. ...
[math]\displaystyle{ f(x) = \begin{cases} 0, & \mbox{for } x \lt 0 \\ x, & \mbox{for } x \geq 0 \end{cases} }[/math]
Range:[math]\displaystyle{ [0, x] }[/math]
Examples: [math]\displaystyle{ f(-5) = 0, f(0) = 0 \;\& \;f(5) = 5 }[/math]
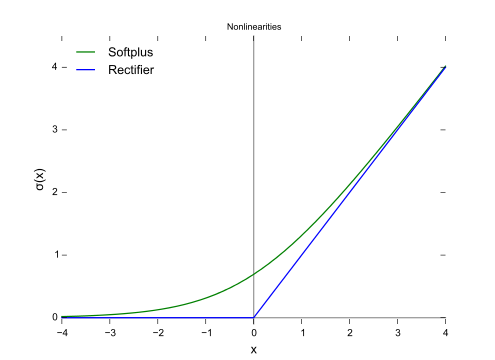
- QUOTE: It trains 6 times faster than tanh. ...
2017b
- (Sze et al., 2017) ⇒ Vivienne Sze, Yu-Hsin Chen, Tien-Ju Yang, and Joel S. Emer. (2017). “Efficient Processing of Deep Neural Networks: A Tutorial and Survey.” Proceedings of the IEEE 105, no. 12
2005
- (Golda, 2005) ⇒ Adam Golda (2005). "Introduction to neural networks"
- QUOTE: ... The other type of activation function is threshold function:
[math]\displaystyle{ y_j=\begin{cases} 1, & \mbox{for } \varphi \gt \varphi_h \\0, & \mbox{for others}\end{cases} \text{with} }[/math]
where [math]\displaystyle{ \varphi_h }[/math] is a given constant threshold value.
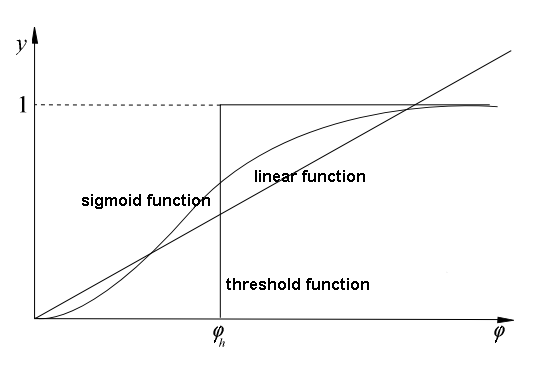
- QUOTE: ... The other type of activation function is threshold function:
1986
- (Williams, 1986) ⇒ Ronald J. Williams. (1986). “The Logic of Activation Functions.” In: (Rumelhart & McClelland, 1986).
- QUOTE: Example 2. [math]\displaystyle{ A=\mathbb{R}, \alpha }[/math] linear (Kohonen,1977).
- ↑ R Hahnloser, R. Sarpeshkar, M A Mahowald, R. J. Douglas, H.S. Seung (2000). Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit. Nature. 405. pp. 947–951.
- ↑ R Hahnloser, H.S. Seung (2001). Permitted and Forbidden Sets in Symmetric Threshold-Linear Networks. NIPS 2001.
- ↑ Xavier Glorot, Antoine Bordes and Yoshua Bengio (2011). Deep sparse rectifier neural networks (PDF). AISTATS.
- ↑ Vinod Nair and Geoffrey Hinton (2010). Rectified linear units improve restricted Boltzmann machines (PDF). ICML.
- ↑ C. Dugas, Y. Bengio, F. Bélisle, C. Nadeau, R. Garcia, NIPS'2000, (2001),Incorporating Second Order Functional Knowledge for Better Option Pricing.
- ↑ László Tóth (2013). Phone Recognition with Deep Sparse Rectifier Neural Networks (PDF). ICASSP.
- ↑ Andrew L. Maas, Awni Y. Hannun, Andrew Y. Ng (2014). Rectifier Nonlinearities Improve Neural Network Acoustic Models