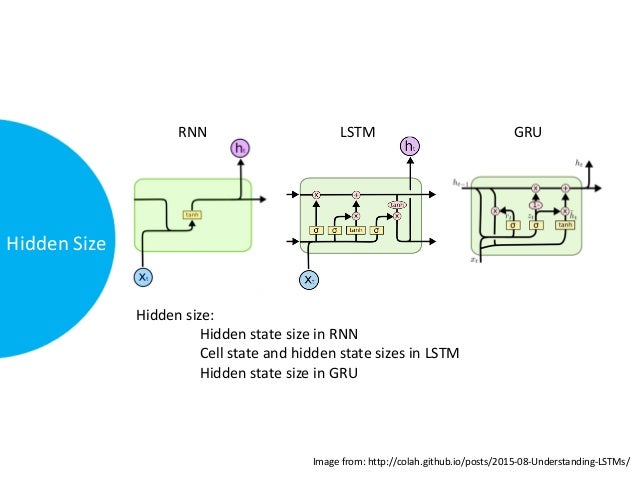
RNN Unit Hidden State
A RNN Unit Hidden State is a hidden state that depends on a previous timestep.
- AKA: RNN State Function.
- Context:
- It can be defined as [math]\displaystyle{ h_t=g(Wx_{t}+U h_{t-1}) }[/math], where [math]\displaystyle{ g }[/math] is a non-linear neuron activation function, [math]\displaystyle{ W }[/math] and [math]\displaystyle{ U }[/math] are a weight matrices, [math]\displaystyle{ x_t }[/math] are updated neural inputs, and [math]\displaystyle{ h_{t-1} }[/math] is the hidden state of previous timestep.
- It decribes the hidden layers of a Recurrent Neural Network.
- Example(s):
- Counter-Example(s)
- See: Visible Neural Network Unit, Artificial Neural Network, Artificial Neuron, Fully-Connected Neural Network Layer, Neuron Activation Function, Neural Network Weight, Neural Network Connection, Neural Network Topology, Multi Hidden Layer NNet.
References
2018
- (Jurasky & Martin, 2018) ⇒ Daniel Jurafsky, and James H. Martin (2018). "Chapter 9 -- Sequence Processing with Recurrent Networks". In: Speech and Language Processing (3rd ed. draft). Draft of September 23, 2018.
- QUOTE: Forward inference (mapping a sequence of inputs to a sequence of outputs) in an SRN is nearly identical to what we’ve already seen with feedforward networks. To compute an output [math]\displaystyle{ y_t }[/math] for an input [math]\displaystyle{ x_t }[/math] , we need the activation value for the hidden layer [math]\displaystyle{ h_t }[/math]. To calculate this, we compute the dot product of the input [math]\displaystyle{ x_t }[/math] with the weight matrix [math]\displaystyle{ W }[/math], and the dot product of the hidden layer from the previous time step [math]\displaystyle{ h_{t−1} }[/math] with the weight matrix [math]\displaystyle{ U }[/math]. We add these values together and pass them through a suitable activation function, [math]\displaystyle{ g }[/math], to arrive at the activation value for the current hidden layer, [math]\displaystyle{ ht }[/math]. Once we have the values for the hidden layer, we proceed with the usual computation to generate the output vector. [math]\displaystyle{ h_t = g(U\;h_{t−1} +W\;x_t) }[/math]
[math]\displaystyle{ y_t = f(Vh_t) }[/math]
In the commonly encountered case of soft classification, finding [math]\displaystyle{ y_t }[/math] consists of a softmax computation that provides a normalized probability distribution over the possible output classes.
- QUOTE: Forward inference (mapping a sequence of inputs to a sequence of outputs) in an SRN is nearly identical to what we’ve already seen with feedforward networks. To compute an output [math]\displaystyle{ y_t }[/math] for an input [math]\displaystyle{ x_t }[/math] , we need the activation value for the hidden layer [math]\displaystyle{ h_t }[/math]. To calculate this, we compute the dot product of the input [math]\displaystyle{ x_t }[/math] with the weight matrix [math]\displaystyle{ W }[/math], and the dot product of the hidden layer from the previous time step [math]\displaystyle{ h_{t−1} }[/math] with the weight matrix [math]\displaystyle{ U }[/math]. We add these values together and pass them through a suitable activation function, [math]\displaystyle{ g }[/math], to arrive at the activation value for the current hidden layer, [math]\displaystyle{ ht }[/math]. Once we have the values for the hidden layer, we proceed with the usual computation to generate the output vector.
2017a
- Yan Kang. (2017). “RNN Explore'. Presentation Slides
- QUOTE:
- QUOTE:
2017
- (Dey & Salem, 2017) ⇒ Rahul Dey, and Fathi M. Salem (2017). "Gate-variants of Gated Recurrent Unit (GRU) neural networks" In: 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, 2017, pp. 1597-1600. doi: 10.1109/MWSCAS.2017.8053243
- QUOTE: : In principal, RNN are more suitable for capturing relationships among sequential data types. The so-called simple RNN has a recurrent hidden state as in [math]\displaystyle{ h_t=g(Wx_t+Uh_{t-1})+b\quad }[/math](1)
where [math]\displaystyle{ x_t }[/math] is the (external) m-dimensional input vector at time [math]\displaystyle{ t }[/math], [math]\displaystyle{ h_t }[/math] the n-dimensional hidden state, [math]\displaystyle{ g }[/math] is the (point-wise) activation function, such as the logistic function, the hyperbolic tangent function, or the rectified Linear Unit (ReLU) [2, 6], and [math]\displaystyle{ W }[/math], [math]\displaystyle{ U }[/math] and [math]\displaystyle{ b }[/math] are the appropriately sized parameters (two weights and bias). Specifically, in this case, [math]\displaystyle{ W }[/math] is an [math]\displaystyle{ n\times m }[/math] matrix, [math]\displaystyle{ U }[/math] is an [math]\displaystyle{ n\times n }[/math] matrix, and [math]\displaystyle{ b }[/math] is an [math]\displaystyle{ n\times 1 }[/math] matrix (or vector).
- QUOTE: : In principal, RNN are more suitable for capturing relationships among sequential data types. The so-called simple RNN has a recurrent hidden state as in
2014
- (Chung et al., 2014) ⇒ Junyoung Chung, Caglar Gulcehre, Kyung Hyun Cho, and Yoshua Bengio. (2014). "Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling". In: Proceedings of the Deep Learning and Representation Learning Workshop at NIPS 2014.
- QUOTE: A recurrent neural network (RNN) is an extension of a conventional feedforward neural network, which is able to handle a variable-length sequence input. The RNN handles the variable-length sequence by having a recurrent hidden state whose activation at each time is dependent on that of the previous time.
More formally, given a sequence [math]\displaystyle{ x = (x_1, x_2, \cdots , x_T ) }[/math], the RNN updates its recurrent hidden state [math]\displaystyle{ h_t }[/math] by
[math]\displaystyle{ h_t=\begin{cases} 0,\quad t=0 \\ \phi(h_{t-1},x_t),\quad otherwise \end{cases} \quad\quad }[/math] (1)where [math]\displaystyle{ \phi }[/math] is a nonlinear function such as composition of a logistic sigmoid with an affine transformation. Optionally, the RNN may have an output [math]\displaystyle{ y = (y_1, y_2, \cdots , y_T ) }[/math] which may again be of variable length.
Traditionally, the update of the recurrent hidden state in Eq. (1) is implemented as
[math]\displaystyle{ h_t = g (Wx_t + Uh_{t−1}),\quad (2) }[/math]where [math]\displaystyle{ g }[/math] is a smooth, bounded function such as a logistic sigmoid function or a hyperbolic tangent function.
- QUOTE: A recurrent neural network (RNN) is an extension of a conventional feedforward neural network, which is able to handle a variable-length sequence input. The RNN handles the variable-length sequence by having a recurrent hidden state whose activation at each time is dependent on that of the previous time.