Retrieval-Augmented Natural Language Generation (RAG) Technique
A Retrieval-Augmented Natural Language Generation (RAG) Technique is an LLM-based algorithm technique that utilizes retrieved text to augment the generation process.
- Context:
- It can (typically) be implemented by a RAG-based System (possibly based on a RAG platform).
- ...
- It can range form being a Any-Domain RAG Technique to being a Domain-Specific RAG Technique (such as legal RAG), depending on domain specificity.
- ...
- It can make use of RAG Algorithm Techniques, such as RAG relevance reorganization.
- It can involve using a knowledge base from which information is retrieved to augment the generation process.
- It can be implemented as a RAG Feature.
- ...
- Example(s):
- Specific Applications:
- GraphRAG Technique: A technique that leverages knowledge graphs to enhance document analysis by representing and organizing relationships between entities within the text.
- Legal Advice RAG Technique: A technique that retrieves case law and statutes from legal databases to provide accurate and context-specific legal guidance based on user queries using a RAG-based system.
- General RAG-Based Algorithms:
- RAG-based QA Algorithm: An Open-Domain QA Algorithm that retrieves relevant information from external knowledge sources in real-time to answer user questions.
- Multi-Agent Recursive Retrieval RAG Technique: A technique where multiple agents collaborate to iteratively retrieve and refine information from a knowledge base, enhancing accuracy and relevance in complex domains like legal document processing.
- Additional RAG Techniques:
- RAG Contextual Compression Technique: A method that compresses the retrieved context during the RAG process, focusing on the most relevant information to optimize the generation task.
- RAG Relevance Reorganization Technique: A method that reorganizes retrieved information based on its relevance to the query, improving the quality and relevance of generated outputs.
- RAG Self-Querying Technique: A self-sufficient RAG technique that autonomously generates additional queries to retrieve more relevant information, refining the input context for better response generation.
- RAG FLARE Technique: A specialized technique designed to improve retrieval speed and efficiency by employing lightweight retrieval mechanisms while maintaining accuracy.
- GraphRAG Technique: A variant of RAG that incorporates knowledge graphs for structuring and retrieving complex, interrelated information to support more precise document generation.
- ...
- Specific Applications:
- Counter-Example(s):
- A simple rule-based chatbot that does not retrieve any data for response generation.
- A neural machine translation system that translates text from one language to another without retrieving any additional information.
- ...
- See: LLM-based Agent Memory Module, Mads' CAS.
References
2024
- (Yang & Chung, 2024) ⇒ Chia Jeng Yang, and Timothy Chung. (2024). “Legal Document RAG: Multi-Graph Multi-Agent Recursive Retrieval through Legal Clauses.” In: Medium - Enterprise RAG.
- NOTES:
- The blogpost contrasts its multi-agent recursive system with traditional Retrieval-Augmented Generation (RAG) models, showing that traditional models can miss key legal references due to a lack of recursive retrieval.
- The blogpost discusses how Recursive Retrieval Process can repeatedly query a knowledge base to refine the accuracy of generated responses, which is crucial for domains requiring high precision like legal document processing.
- The blogpost explores the application of Multi-Agent RAG Systems where multiple agents collaborate to retrieve and process complex legal information, leading to more comprehensive results.
- The blogpost explains the use of a Clause-Level Retrieval mechanism, allowing for targeted retrieval of legal clauses relevant to the query, ensuring more precise generation of legal advice or documentation.
- NOTES:
2024
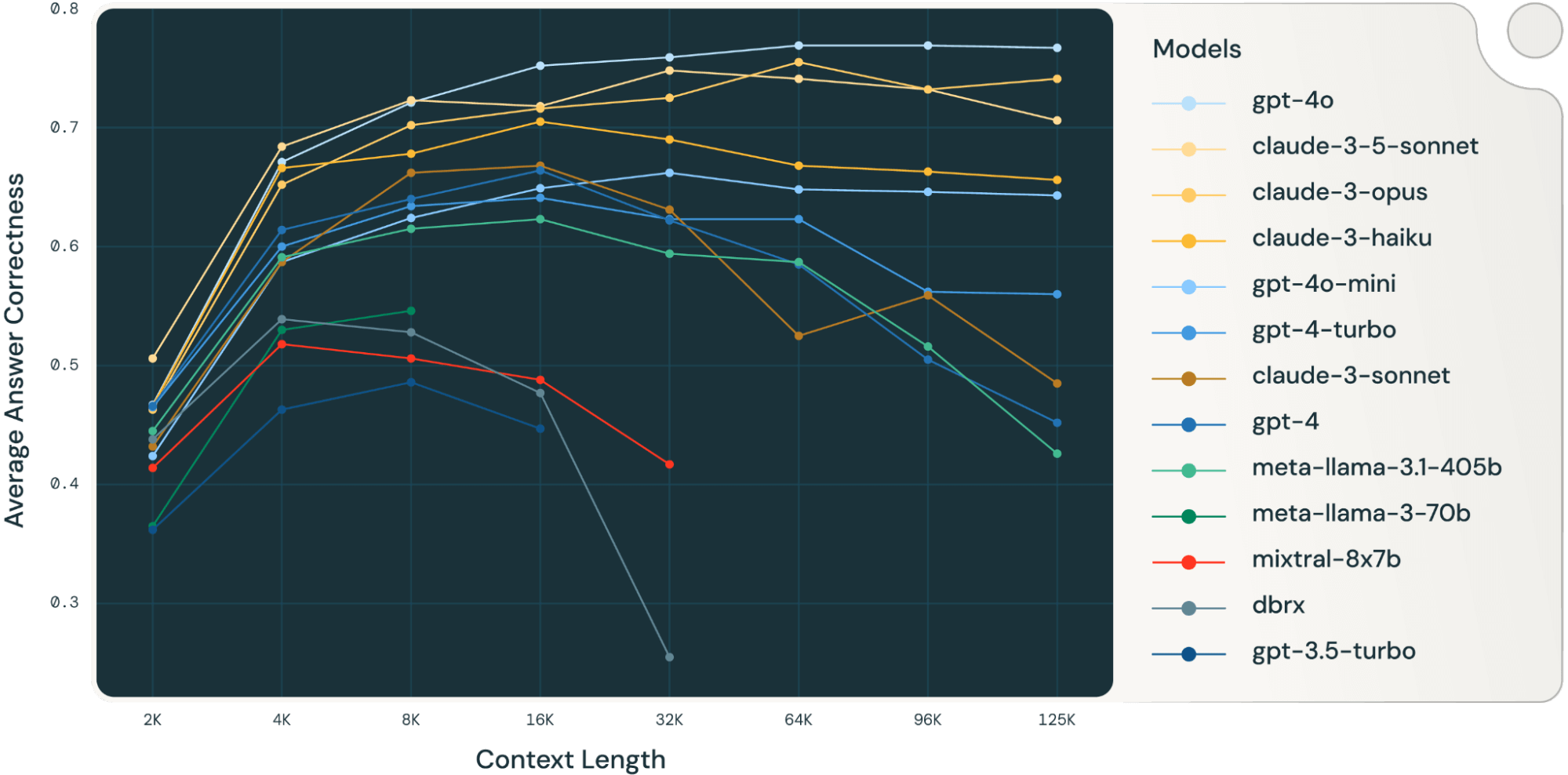
- (Leng et al., 2024) ⇒ Quinn Leng, Jacob Portes, Sam Havens, Matei Zaharia, and Michael Carbin. (2024). “Long Context RAG Performance of LLMs.” In: Mosaic AI Research.
- NOTES: It explores the impact of increased context length on the quality of Retrieval-Augmented Generation (RAG) applications in large language models (LLMs).
2024
- (Gao et al., 2024) ⇒ Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang, and Haofen Wang. (2024). “Retrieval-Augmented Generation for Large Language Models: A Survey.” doi:10.48550/arXiv.2312.10997
- NOTES:
- It details RAG's integration in LLMs for handling challenges like hallucination and outdated knowledge, enhancing accuracy by merging intrinsic knowledge with dynamic external databases.
- It explores RAG's evolution across Naive, Advanced, and Modular frameworks, focusing on improvements in retrieval, generation, and augmentation techniques.
- It highlights RAG's role in mitigating LLM limitations for domain-specific queries through external data retrieval, enhancing response accuracy and relevance.
- It delineates the progression of RAG research, from initial knowledge assimilation efforts to a hybrid approach combining RAG and fine-tuning for LLM controllability.
- It emphasizes RAG's systematic approach, incorporating cutting-edge retrieval and integration methods, and introduces evaluation metrics for RAG models.
- It breaks down RAG's framework into distinct paradigms, discussing improvements in retrieval quality and the introduction of novel modules like Search and Memory.
- It delves into RAG's generation phase, discussing strategies for post-retrieval processing and LLM fine-tuning to enhance response quality and relevance.
- It discusses RAG's augmentation stage, detailing pre-training, fine-tuning, and inference stages, and the use of structured and unstructured data for improved context.
- It compares RAG and fine-tuning in LLM optimization, highlighting their differences in knowledge updates, model customization, and computational resource requirements.
- It concludes with future prospects for RAG, outlining ongoing challenges, expansion into multimodal domains, and the growing ecosystem of RAG technologies.
- NOTES:
2023
- (Shen, Geng et al., 2023) ⇒ Tao Shen, Xiubo Geng, Chongyang Tao, Can Xu, Guodong Long, Kai Zhang, and Daxin Jiang. (2023). “Unifier: A Unified Retriever for Large-scale Retrieval.” In: Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. doi:10.1145/3580305.3599927
- QUOTE: ... Task Definition. Given a collection with numerous documents (i.e., [math]\displaystyle{ D = \{d_i\}_{i=1}^{|D|} }[/math]) and a textual query [math]\displaystyle{ q }[/math] from users, a retriever aims to fetch a list of text pieces [math]\displaystyle{ \bar{D}_q }[/math] to contain all relevant ones. Generally, this is based on a relevance score between [math]\displaystyle{ q }[/math] and every document [math]\displaystyle{ d_i }[/math] in a Siamese manner, i.e., [math]\displaystyle{ \langle \text{Enc}(q), \text{Enc}(d_i) \rangle }[/math], where Enc is an arbitrary representation model (e.g., Bag-of-Words and neural encoders) and [math]\displaystyle{ \langle \cdot, \cdot \rangle }[/math] denotes a lightweight relevance metric (e.g., BM25 and dot-product). ...
2022
- https://docs.aws.amazon.com/sagemaker/latest/dg/jumpstart-foundation-models-customize-rag.html
- QUOTE: Foundation models are usually trained offline, making the model agnostic to any data that is created after the model was trained. Additionally, foundation models are trained on very general domain corpora, making them less effective for domain-specific tasks. You can use Retrieval Augmented Generation (RAG) to retrieve data from outside a foundation model and augment your prompts by adding the relevant retrieved data in context. For more information about RAG model architectures, see Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
With RAG, the external data used to augment your prompts can come from multiple data sources, such as a document repositories, databases, or APIs. The first step is to convert your documents and any user queries into a compatible format to perform relevancy search. To make the formats compatible, a document collection, or knowledge library, and user-submitted queries are converted to numerical representations using embedding language models. Embedding is the process by which text is given numerical representation in a vector space. RAG model architectures compare the embeddings of user queries within the vector of the knowledge library. The original user prompt is then appended with relevant context from similar documents within the knowledge library. This augmented prompt is then sent to the foundation model. You can update knowledge libraries and their relevant embeddings asynchronously.

- QUOTE: Foundation models are usually trained offline, making the model agnostic to any data that is created after the model was trained. Additionally, foundation models are trained on very general domain corpora, making them less effective for domain-specific tasks. You can use Retrieval Augmented Generation (RAG) to retrieve data from outside a foundation model and augment your prompts by adding the relevant retrieved data in context. For more information about RAG model architectures, see Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
2020
- https://github.com/facebookresearch/DPR
- QUOTE: Dense Passage Retrieval (DPR) - is a set of tools and models for state-of-the-art open-domain Q&A research. It is based on the following paper: (Karpukhin et al., 2020)
2020
- https://ai.facebook.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models/
- QUOTE: RAG looks and acts like a standard seq2seq model, meaning it takes in one sequence and outputs a corresponding sequence. There is an intermediary step though, which differentiates and elevates RAG above the usual seq2seq methods. Rather than passing the input directly to the generator, RAG instead uses the input to retrieve a set of relevant documents, in our case from Wikipedia.
Given the prompt “When did the first mammal appear on Earth?” for instance, RAG might surface documents for “Mammal,” “History of Earth,” and “Evolution of Mammals.” These supporting documents are then concatenated as context with the original input and fed to the seq2seq model that produces the actual output. RAG thus has two sources of knowledge: the knowledge that seq2seq models store in their parameters (parametric memory) and the knowledge stored in the corpus from which RAG retrieves passages (nonparametric memory).
These two sources complement each other. We found that RAG uses its nonparametric memory to “cue” the seq2seq model into generating correct responses, essentially combining the flexibility of the “closed-book” or parametric-only approach with the performance of “open-book” or retrieval-based methods. RAG employs a form of late fusion to integrate knowledge from all retrieved documents, meaning it makes individual answer predictions for document-question pairs and then aggregates the final prediction scores. Critically, using late fusion allows us to back-propagate error signals in the output to the retrieval mechanism, which can substantially improve the performance of the end-to-end system.
- Combining a retrieval-based component with a generative component has advantages even in purely extractive tasks, such as the open-domain NaturalQuestions task. Performance improves when RAG has access to documents that contain clues to the correct answer but where the answer is never stated verbatim, and RAG even generates correct answers in certain situations where the correct answer is nowhere to be found in any of the retrieved documents. We obtained very strong results on NaturalQuestions, CuratedTrec, and WebQuestions with RAG, demonstrating that state-of-the-art machine reading performance can be achieved with a generative, rather than extractive, reader..
- QUOTE: RAG looks and acts like a standard seq2seq model, meaning it takes in one sequence and outputs a corresponding sequence. There is an intermediary step though, which differentiates and elevates RAG above the usual seq2seq methods. Rather than passing the input directly to the generator, RAG instead uses the input to retrieve a set of relevant documents, in our case from Wikipedia.
2020
- (Lewis et al., 2020) ⇒ Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. (2020). “Retrieval-Augmented Generation for Knowledge-intensive NLP Tasks.” In: Advances in Neural Information Processing Systems, 33.
2020
- (Karpukhin et al., 2020) ⇒ Vladimir Karpukhin, Barlas Oguz, Seo Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. (2020). “Dense Passage Retrieval for Open-Domain Question Answering." In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 6769-6781).