Gated Recurrent Unit (GRU)
Jump to navigation
Jump to search
A Gated Recurrent Unit (GRU) is a hidden unit that is a sequential memory cell consisting of a reset gate and an update gate but no output gate.
- Context:
- It can (typically) be a part of an GRU Network.
- It can be mathematically described by a gated recurrent hidden state.
- Example(s)
- GRU gating mechanism proposed by Chung et al. (2014),
- …
- Counter-Example(s):
- a Standard RNN Unit.
- an LSTM Unit.
- See: GRU Training Algorithm, GRU Network, RLU Unit, Recurrent Neural Network.
References
2016
- (WILDML) ⇒ "Recurrent Neural Network Tutorial, Part 4 – Implementing a GRU/LSTM RNN with Python and Theano – WildML". Wildml.com. Retrieved May 18, 2016.
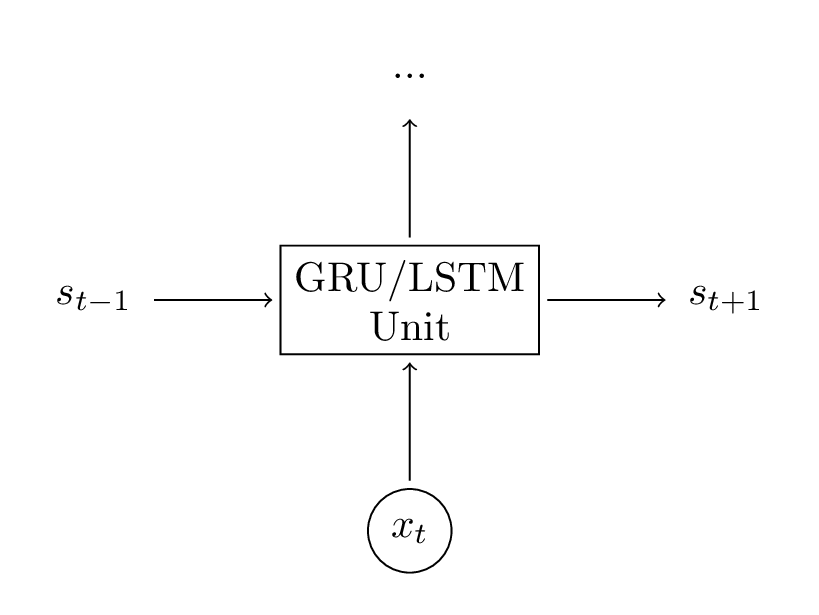
- QUOTE: The inputs to this unit were xt, the current input at step t, and s_t-1, the previous hidden state. The output was a new hidden state st. A LSTM unit does the exact same thing, just in a different way! This is key to understanding the big picture. You can essentially treat LSTM (and GRU) units as a black boxes. Given the current input and previous hidden state, they compute the next hidden state in some way.
2017
- (DL4J, 2017) ⇒ https://deeplearning4j.org/lstm.html
- QUOTE: … A gated recurrent unit (GRU) is basically an LSTM without an output gate, which therefore fully writes the contents from its memory cell to the larger net at each time step. …
2014a
- (Chung et al., 2014) ⇒ Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio (2014). "Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling". arXiv:1412.3555.
- QUOTE: It is easy to notice similarities between the LSTM unit and the GRU from Fig. 1.
The most prominent feature shared between these units is the additive component of their update from t to t + 1, which is lacking in the traditional recurrent unit. The traditional recurrent unit always replaces the activation, or the content of a unit with a new value computed from the current input and the previous hidden state. On the other hand, both LSTM unit and GRU keep the existing content and add the new content on top of it (...)

- QUOTE: It is easy to notice similarities between the LSTM unit and the GRU from Fig. 1.

- Figure 1: Illustration of (a) LSTM and (b) gated recurrent units. (a) [math]\displaystyle{ i }[/math], [math]\displaystyle{ f }[/math] and [math]\displaystyle{ o }[/math] are the input, forget and output gates, respectively. [math]\displaystyle{ c }[/math] and [math]\displaystyle{ \tilde{c} }[/math] denote the memory cell and the new memory cell content. (b) [math]\displaystyle{ r }[/math] and [math]\displaystyle{ z }[/math] are the reset and update gates, and [math]\displaystyle{ h }[/math] and [math]\displaystyle{ \tilde{h} }[/math] are the activation and the candidate activation.
2014b
- (Cho et al., 2014) ⇒ Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. (2014). “Learning Phrase Representations Using RNN Encoder-decoder for Statistical Machine Translation”. arXiv preprint arXiv:1406.1078
- ABSTRACT: In this paper, we propose a novel neural network model called RNN Encoder-Decoder that consists of two recurrent neural networks (RNN). One RNN encodes a sequence of symbols into a fixed-length vector representation, and the other decodes the representation into another sequence of symbols. The encoder and decoder of the proposed model are jointly trained to maximize the conditional probability of a target sequence given a source sequence. The performance of a statistical machine translation system is empirically found to improve by using the conditional probabilities of phrase pairs computed by the RNN Encoder-Decoder as an additional feature in the existing log-linear model. Qualitatively, we show that the proposed model learns a semantically and syntactically meaningful representation of linguistic phrases.