Compressed Deep Neural Network
A Compressed Deep Neural Network is a Deep Neural Network which size has been reduced by a DNN Compression System without affecting the original accuracy.
- AKA: Compressed DNN.
- Context:
- …
- Example(s):
- an ENet,
- a MobileNet,
- a SegNet,
- a SqueezeDet,
- a SqueezeNet,
- a SqueezeNext,
- Counter-Example(s):.
- an AlexNet,
- a DenseNet,
- a GoogLeNet,
- an InceptionV3,
- a VGG CNN.
- See: Neural Network Pruning Task, Neural Network Quantization Task, Neural Network Weight Sharing Task, Huffman Coding Algorithm, Huffman Tree, DSD Regularization Task, Efficient Inference Engine.
References
2016a
- (Han et al., 2016) ⇒ Song Han, Huizi Mao, and William J. Dally (2015). "Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding". arXiv eprint:1510.00149.
- QUOTE: Our goal is to reduce the storage and energy required to run inference on such large networks so they can be deployed on mobile devices. To achieve this goal, we present “deep compression”: a three stage pipeline (Figure 1) to reduce the storage required by neural network in a manner that preserves the original accuracy. First, we prune the networking by removing the redundant connections, keeping only the most informative connections. Next, the weights are quantized so that multiple connections share the same weight, thus only the codebook (effective weights) and the indices need to be stored. Finally, we apply Huffman coding to take advantage of the biased distribution of effective weights.

Figure 1: The three stage compression pipeline: pruning, quantization and Huffman coding. Pruning reduces the number of weights by 10×, while quantization further improves the compression rate: between 27× and 31×. Huffman coding gives more compression: between 35× and 49×. The compression rate already included the meta-data for sparse representation. The compression scheme doesn’t incur any accuracy loss.
- QUOTE: Our goal is to reduce the storage and energy required to run inference on such large networks so they can be deployed on mobile devices. To achieve this goal, we present “deep compression”: a three stage pipeline (Figure 1) to reduce the storage required by neural network in a manner that preserves the original accuracy. First, we prune the networking by removing the redundant connections, keeping only the most informative connections. Next, the weights are quantized so that multiple connections share the same weight, thus only the codebook (effective weights) and the indices need to be stored. Finally, we apply Huffman coding to take advantage of the biased distribution of effective weights.

2016b
- (Han et al., 2016b) ⇒ Song Han, Xingyu Liu, Huizi Mao, Jing Pu, Ardavan Pedram, Mark A. Horowitz, and William J. Dally (2016, June)."EIE: efficient inference engine on compressed deep neural network. In: Computer Architecture (ISCA), 2016_ACM/IEEE 43rd Annual International Symposium on (pp. 243-254). IEEE:7551397, arXiv e-print: 1602.01528 , DOI: 10.1109/ISCA.2016.30.
- QUOTE: Network compression via pruning and weight sharing [16] makes it possible to fit modern networks such as AlexNet (60M parameters, 240MB), and VGG-16 (130M parameters, 520MB) in on-chip SRAM. Processing these compressed models, however, is challenging. With pruning, the matrix becomes sparse and the indices become relative. With weight sharing, we store only a short (4-bit) index for each weight. This adds extra levels of indirection that cause complexity and inefficiency on CPUs and GPUs.
To efficiently operate on compressed DNN models, we propose EIE, an efficient inference engine, a specialized accelerator that performs customized sparse matrix vector multiplication and handles weight sharing with no loss of efficiency. EIE is a scalable array of processing elements (PEs). Every PE stores a partition of network in SRAM and performs the computations associated with that part. It takes advantage of dynamic input vector sparsity, static weight sparsity, relative indexing, weight sharing and extremely narrow weights (4bits).

Figure 1. Efficient inference engine that works on the compressed deep neural network model for machine learning applications.
- QUOTE: Network compression via pruning and weight sharing [16] makes it possible to fit modern networks such as AlexNet (60M parameters, 240MB), and VGG-16 (130M parameters, 520MB) in on-chip SRAM. Processing these compressed models, however, is challenging. With pruning, the matrix becomes sparse and the indices become relative. With weight sharing, we store only a short (4-bit) index for each weight. This adds extra levels of indirection that cause complexity and inefficiency on CPUs and GPUs.

2016c
- (Lorica, 2016) ⇒ Ben Lorica (January 21, 2016). "Compressed representations in the age of big data. Emerging trends in intelligent mobile applications and distributed computing".
- QUOTE: One solution is to significantly reduce the size of deep learning models. CVA researchers recently proposed a general scheme for compressing deep neural networks in three steps:
- prune the unimportant connections,
- quantize the network and enforce weight sharing,
- and finally apply Huffman encoding.
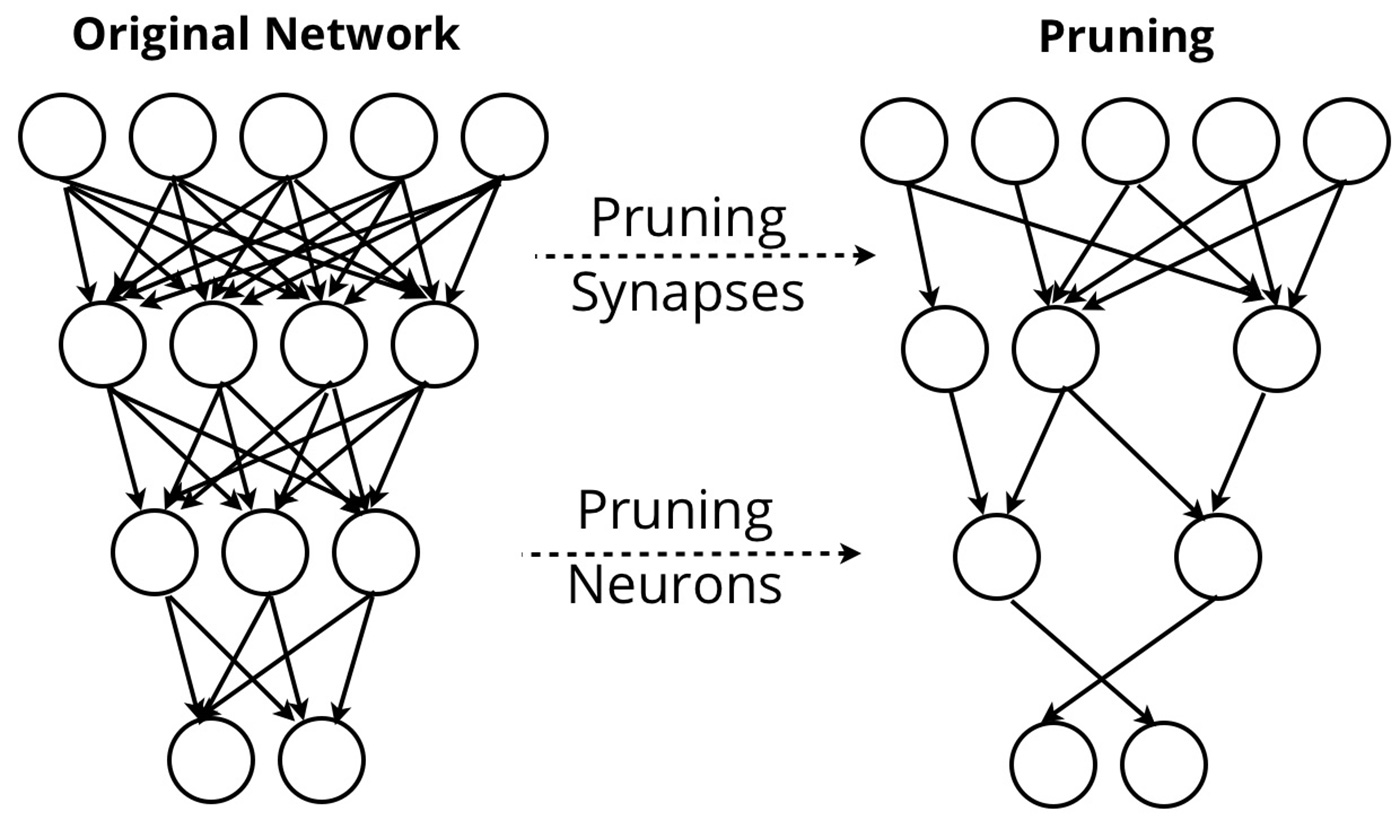
Figure 1. Sample diagram comparing compression schemes on neural network sizes. Image courtesy of Ben Lorica.
- QUOTE: One solution is to significantly reduce the size of deep learning models. CVA researchers recently proposed a general scheme for compressing deep neural networks in three steps:
- Initial experiments showed their compression scheme reduced neural network sizes by 35 to 50 times, and the resulting compressed models were able to match the accuracy of the corresponding original models. CVA researchers also designed an accompanying energy-efficient ASIC accelerator for running compressed deep neural networks, hinting at next-generation software + hardware designed specifically for intelligent mobile applications.