CogStack Pipeline
A CogStack Pipeline is a Data Processing Pipeline for the CogStack Ecosystem.
- AKA:
cogstack-pipeline. - Context:
- GitHub Repository: https://github.com/CogStack/CogStack-Pipeline
- It is based on Java Spring Batch framework.
- …
- Example(s):
- …
- Counter-Example(s):
- See:, SemEHR System, Semantic Web Search System, Semantic Web, Ontology Search System, Natural Language Processing, Annotation Task, Electronic Health Record, Clinical Trial.
References
2019a
- (Roguski, 2019) ⇒ Lukasz Roguski (Apr, 2019). "CogStack platform"
- QUOTE: The data processing workflow of CogStack is based on Java Spring Batch framework. Not to dwell too much into technical details and just to give a general idea – the data is being read in batches from a predefined data source, later it follows a number of processing operations with the final result stored in a predefined data sink. CogStack implements variety of data processors, data readers and writers with scalability mechanisms that can be specified in CogStack job configuration.
Each CogStack data processing pipeline is configured using a number of parameters defined in the corresponding Java properties file. Moreover, multiple CogStack data processing pipelines can be launched in parallel or chained together (see Examples), each using its own properties configuration file.
(...) CogStack data processing pipeline design follows the principles behind Spring Batch. That is, there are different Jobs and Steps and custom processing components called ItemReaders , ItemWriters and ItemProcessors . A Job has one to many Step, which has exactly one ItemReader, ItemProcessor, and ItemWriter. A Job needs to be launched by JobLauncher, and meta data about the currently running process needs to be stored in JobRepository. The picture below presents a simplified version of a reference batch processing architecture.
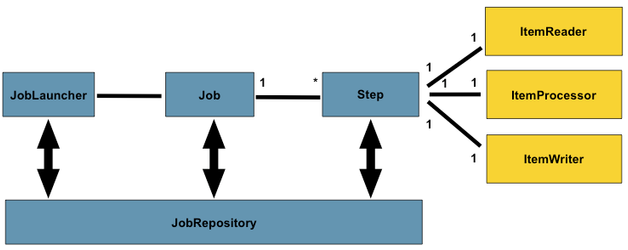
- QUOTE: The data processing workflow of CogStack is based on Java Spring Batch framework. Not to dwell too much into technical details and just to give a general idea – the data is being read in batches from a predefined data source, later it follows a number of processing operations with the final result stored in a predefined data sink. CogStack implements variety of data processors, data readers and writers with scalability mechanisms that can be specified in CogStack job configuration.
2019b
- (Roguski, 2019) ⇒ Lukasz Roguski (Jan, 2019). "CogStack platform"
- QUOTE: Below is presented is one of the most simple and common scenarios when ingesting and processing the EHR data from a proprietary data source.
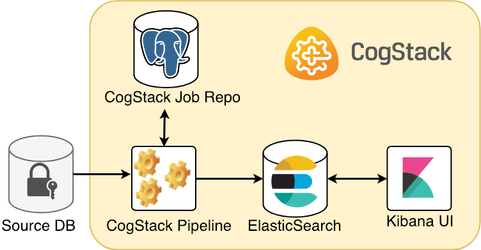
A CogStack platform presented here consists of such core services:
- CogStack Pipeline service for ingesting and processing the EHR data from the source database,
- CogStack Job Repository (PostgreSQL database) serving for job status control,
- ElasticSearch sink where the processed EHR records are stored,
- (optional) Kibana user interface to easily perform exploratory data analysis over the processed records.
- QUOTE: Below is presented is one of the most simple and common scenarios when ingesting and processing the EHR data from a proprietary data source.
2018a
- (Jackson et al., 2018) ⇒ Richard Jackson, Ismail Kartoglu, Clive Stringer, Genevieve Gorrell, Angus Roberts, Xingyi Song, Honghan Wu, Asha Agrawal, Kenneth Lui, Tudor Groza, Damian Lewsley, Doug Northwood, Amos Folarin, Robert Stewart, and Richard Dobson. (2018). “CogStack - Experiences of Deploying Integrated Information Retrieval and Extraction Services in a Large National Health Service Foundation Trust Hospital.” In: BMC Medical Informatics and Decision Making Journal, 18(47). doi:10.1186/s12911-018-0623-9