Chain-of-Thought (CoT) Prompting Method
A Chain-of-Thought (CoT) Prompting Method is a prompt engineering method that requires the LLM to express its reply as chained reasoning steps.
- AKA: CoT, Step-by-Step Reasoning, Thought Chain Prompting.
- Context:
- It can (typically) be used for both Text Generation tasks and symbolic reasoning tasks, increasing the model's ability to handle complex reasoning.
- It can (typically) enhance large language model performance on tasks requiring multi-step problem solving such as mathematical word problems and logical puzzles.
- It can (typically) improve interpretability by making the model's reasoning process explicit and transparent to human observers.
- It can (often) involve simple prompts like "Let's think step-by-step," guiding the model to break down tasks into smaller reasoning units.
- It can (often) reduce reasoning errors by allowing the model to catch logical mistakes during the explicit reasoning process.
- It can (often) serve as a reasoning scaffold that helps models tackle problems that would be difficult to solve directly.
- ...
- It can range from being a Zero-Shot CoT Prompting Method to being a One-Shot CoT Prompting Method.
- It can range from being a Simple CoT Method to being a Complex CoT Method, depending on its task complexity.
- It can range from being a Generic CoT Approach to being a Domain-Specific CoT Approach, depending on its application context.
- ...
- It can improve Logical Reasoning Skill in models, particularly for tasks requiring multi-step solutions, such as arithmetic and commonsense reasoning.
- It can serve as an effective Cognitive Intervention Technique that encourages individuals or models to generate a chain of related thoughts (enhancing memory retention and problem-solving skills).
- It can involve models generating intermediate steps, like those used to solve mathematical problems, providing greater transparency and interpretability.
- It can emerge as an emergent property in large language models with sufficient parameter size, typically around 100 billion parameters and above.
- It can increase token consumption significantly compared to direct answering, requiring more computational resources for both inference and response generation.
- It can be combined with self-consistency techniques to generate multiple reasoning paths and select the most common answer, further improving accuracy.
- ...
- Example(s):
- One-Shot CoT Prompting, where the model is given one example of chained reasoning before solving a similar problem on its own, such as:
- Think-Step-by-Step Prompting, which explicitly encourages models to approach the problem-solving process step-by-step.
- Zero-Shot CoT Prompting, which uses simple instructions like "Let's think step-by-step" without providing explicit reasoning examples.
- Few-Shot CoT Prompting, which provides multiple examples of reasoning chains to guide the model's approach to new problems.
- Self-Consistency CoT Method, which generates multiple reasoning chains and selects the most common answer to improve reliability.
- Domain-Specific CoT Prompting, with specialized prompt patterns optimized for particular domains like:
- Mathematical CoT Prompting for solving arithmetic problems and algebraic expressions.
- Logical CoT Prompting for addressing symbolic reasoning tasks and syllogisms.
- Commonsense CoT Prompting for handling everyday reasoning scenarios and situational judgment.
- ...
- One-Shot CoT Prompting, where the model is given one example of chained reasoning before solving a similar problem on its own, such as:
- Counter-Example(s):
- Tree of Thought (ToT) Prompting, where models explore multiple possible reasoning paths using tree structures rather than linear chains.
- Example-Conditioned Generation Method, which focuses on generating responses based on pre-defined examples rather than reasoning through steps.
- Just-Give-Me-The-Answer Method, which provides only a final output (without intermediate reasoning steps).
- Chain of Draft (CoD) Prompting Method, which encourages minimalistic intermediate reasoning outputs rather than verbose step-by-step explanations.
- Graph of Thought Method, which structures reasoning as interconnected nodes in a graph rather than sequential steps.
- Skeleton-of-Thought Method, which first outlines a reasoning structure before filling in details.
- See: PromptChainer, Soft Prompt Tuning, Automatic Prompt Engineering (APE), Reasoning Paradigm, Multi-Step Reasoning Task, Reasoning Verbosity Spectrum.
References
2023
- (Wikipedia, 2023) ⇒ https://en.wikipedia.org/wiki/Prompt_engineering#Chain-of-thought Retrieved:2023-5-11.
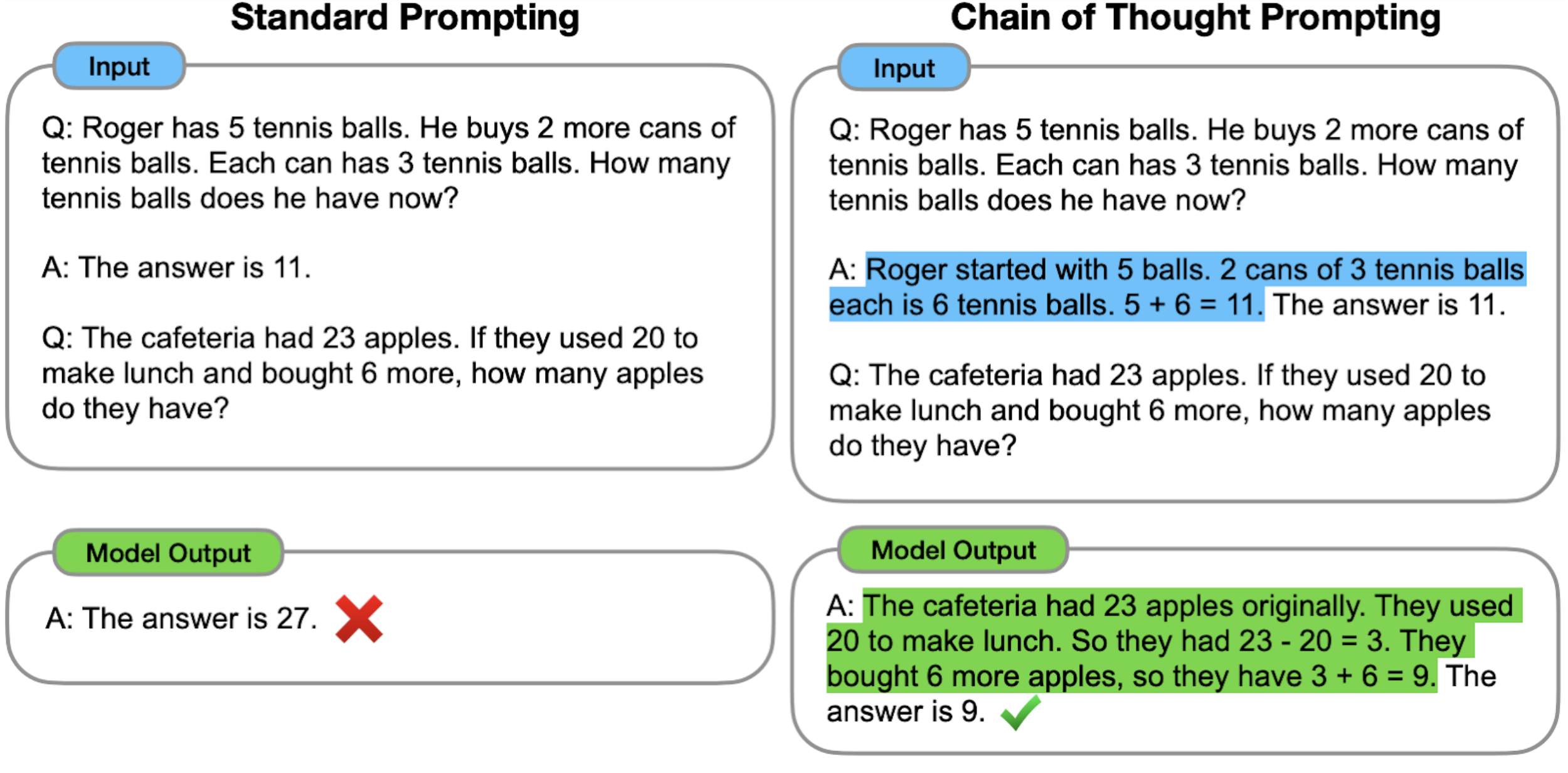
- Chain-of-thought prompting (CoT) improves the reasoning ability of LLMs by prompting them to generate a series of intermediate steps that lead to the final answer of a multi-step problem. The technique was first proposed by Google researchers in 2022.[1]
LLMs that are trained on large amounts of text using deep learning methods can generate output that resembles human-generated text. While LLMs show impressive performance on various natural language tasks, they still face difficulties with some reasoning tasks that require logical thinking and multiple steps to solve, such as arithmetic or commonsense reasoning questions. To address this challenge, CoT prompting prompts the model to produce intermediate reasoning steps before giving the final answer to a multi-step problem.[1]
For example, given the question “Q: The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?”, a CoT prompt might induce the LLM to answer with steps of reasoning that mimic a train of thought like “A: The cafeteria had 23 apples originally. They used 20 to make lunch. So they had 23 - 20 = 3. They bought 6 more apples, so they have 3 + 6 = 9. The answer is 9.”[1]
Chain-of-thought prompting improves the performance of LLMs on average on both arithmetic and commonsense tasks in comparison to standard prompting methods. When applied to PaLM, a 540B parameter language model, CoT prompting significantly aided the model, allowing it to perform comparably with task-specific fine-tuned models on several tasks, even setting a new state of the art at the time on the GSM8K mathematical reasoning benchmark.[1]
CoT prompting is an emergent property of model scale, meaning it works better with larger and more powerful language models. [1] It is possible to fine-tune models on CoT reasoning datasets to enhance this capability further and stimulate better interpretability.
- There are two main methods to elicit chain-of-thought reasoning: few-shot prompting and zero-shot prompting. The initial proposition of CoT prompting demonstrated few-shot prompting, wherein at least one example of a question paired with proper human-written CoT reasoning is prepended to the prompt.[1] It is also possible to elicit similar reasoning and performance gain with zero-shot prompting, which can be as simple as appending to the prompt the words "Let's think step-by-step". This allows for better scaling as one no longer needs to prompt engineer specific CoT prompts for each task to get the corresponding boost in performance.[2]
- Chain-of-thought prompting (CoT) improves the reasoning ability of LLMs by prompting them to generate a series of intermediate steps that lead to the final answer of a multi-step problem. The technique was first proposed by Google researchers in 2022.[1]
- ↑ 1.0 1.1 1.2 1.3 1.4 1.5 Wei, Jason; Wang, Xuezhi; Schuurmans, Dale; Bosma, Maarten; Ichter, Brian; Xia, Fei; Chi, Ed H.; Le, Quoc V.; Zhou, Denny (31 October 2022). "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models". arXiv:2201.11903
- ↑ Dickson, Ben (30 August 2022). "LLMs have not learned our language — we're trying to learn theirs". VentureBeat. Retrieved 10 March 2023. Shaikh, Omar; Zhang, Hongxin; Held, William; Bernstein, Michael; Yang, Diyi (2022). “On Second Thought, Let's Not Think Step by Step! Bias and Toxicity in Zero-Shot Reasoning". arXiv:2212.08061.
2022
- (Wang et al., 2022) ⇒ Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, and Denny Zhou. (2022). “Self-Consistency Improves Chain of Thought Reasoning in Language Models.” arXiv preprint arXiv:2203.11171
2022
- https://ai.googleblog.com/2022/05/language-models-perform-reasoning-via.html
- QUOTE: ... In chain of thought prompting (below, right), the model is prompted to produce intermediate reasoning steps before giving the final answer to a multi-step problem. The idea is that a model-generated chain of thought would mimic an intuitive thought process when working through a multi-step reasoning problem. ...
2022
- (Kojima et al., 2022) ⇒ Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. (2022). “Large Language Models Are Zero-shot Reasoners.” In: Advances in Neural Information Processing Systems, 35.
2022
- (Wei, Wang et al., 2022) ⇒ Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. (2022). “Chain of Thought Prompting Elicits Reasoning in Large Language Models.” In: arXiv preprint arXiv:2201.11903. doi:10.48550/arXiv.2201.11903
- QUOTE: ... We explore how generating a chain of thought -- a series of intermediate reasoning steps -- significantly improves the ability of large language models to perform complex reasoning. In particular, we show how such reasoning abilities emerge naturally in sufficiently large language models via a simple method called chain of thought prompting, where a few chain of thought demonstrations are provided as exemplars in prompting. Experiments on three large language models show that chain of thought prompting improves performance on a range of arithmetic, commonsense, and symbolic reasoning tasks. The empirical gains can be striking. ...
- NOTES:
- The paper introduces Chain-of-Thought (CoT) prompting, which improves the ability of large language models (LLMs) to perform complex reasoning tasks by generating a series of intermediate reasoning steps.
- The paper demonstrates that CoT prompting outperforms standard prompting in arithmetic, commonsense, and symbolic reasoning tasks, showcasing significant gains in performance.
- The paper highlights that CoT prompting is most effective when applied to LLMs with over 100 billion parameters, such as PaLM 540B and GPT-3 175B.
- The paper shows that CoT prompting allows models to decompose multi-step problems, enhancing interpretability and enabling models to tackle more complex tasks.