2024 CanAIScalingContinueThrough2030
- (Sevilla et al., 2024) ⇒ Jaime Sevilla, Tamay Besiroglu, Ben Cottier, Josh You, Edu Roldán, Pablo Villalobos, and Ege Erdil. (2024). “Can AI Scaling Continue Through 2030?.” Epoch AI.
Subject Headings: AI Scaling Laws, Power Availability for AI, Chip Manufacturing Capacity, Data Scarcity for AI Training, Latency in AI Systems, Economic Investment in AI Scaling, AI Infrastructure Development.
Notes
Here are the revised bullet points following your specified pattern:
- The article examines the feasibility of continuing the current trend of scaling AI training compute at a rate of approximately 4x per year through 2030, identifying major constraints such as power constraints, chip manufacturing constraints, data availability constraints, and system latency constraints.
- The article estimates that training runs involving around 2e29 FLOP are likely feasible by 2030, representing a significant increase in computational power compared to current AI models.
- The article highlights power availability as one of the key limiting factors for large-scale AI training, predicting that power demands for AI data centers could rise up to 200 times by 2030 compared to current frontier models.
- The article projects that chip manufacturing capacity will need to scale significantly, with growth in advanced packaging and high-bandwidth memory production, potentially enabling the use of up to 100 million H100-equivalent GPUs dedicated to AI training by 2030.
- The article discusses how multimodal data and synthetic data can address data scarcity constraints, suggesting that these new data sources could expand training datasets, supporting training runs up to 2e32 FLOP.
- The article explores the latency wall as a potential barrier to AI scaling, caused by communication delays between GPUs during training, and suggests mitigating strategies such as distributed training and batch size optimization.
- The article emphasizes that power constraints for geographically localized data centers will require innovative solutions like geographically distributed training networks to manage both power demands and bandwidth constraints.
- The article notes that the expansion of the power grid and construction of new power infrastructure will be essential, predicting that large-scale power plants exceeding 3-5 GW will be needed to sustain AI training at the projected scale.
- The article indicates that synthetic data generation could help mitigate the training data bottleneck, while cautioning about risks such as model collapse and the significant computational costs associated with generating high-quality synthetic data.
- The article predicts that despite these constraints, the scalability of AI models could continue to improve significantly, potentially leading to models that exceed GPT-4 in scale to a similar degree that GPT-4 surpasses GPT-2.
- The article concludes that while the major challenges to AI scaling—including power constraints, chip production constraints, data scarcity, and latency constraints—are substantial, they can be overcome with significant investment, possibly driving hundreds of billions of dollars in AI infrastructure by 2030.
Cited By
Quotes
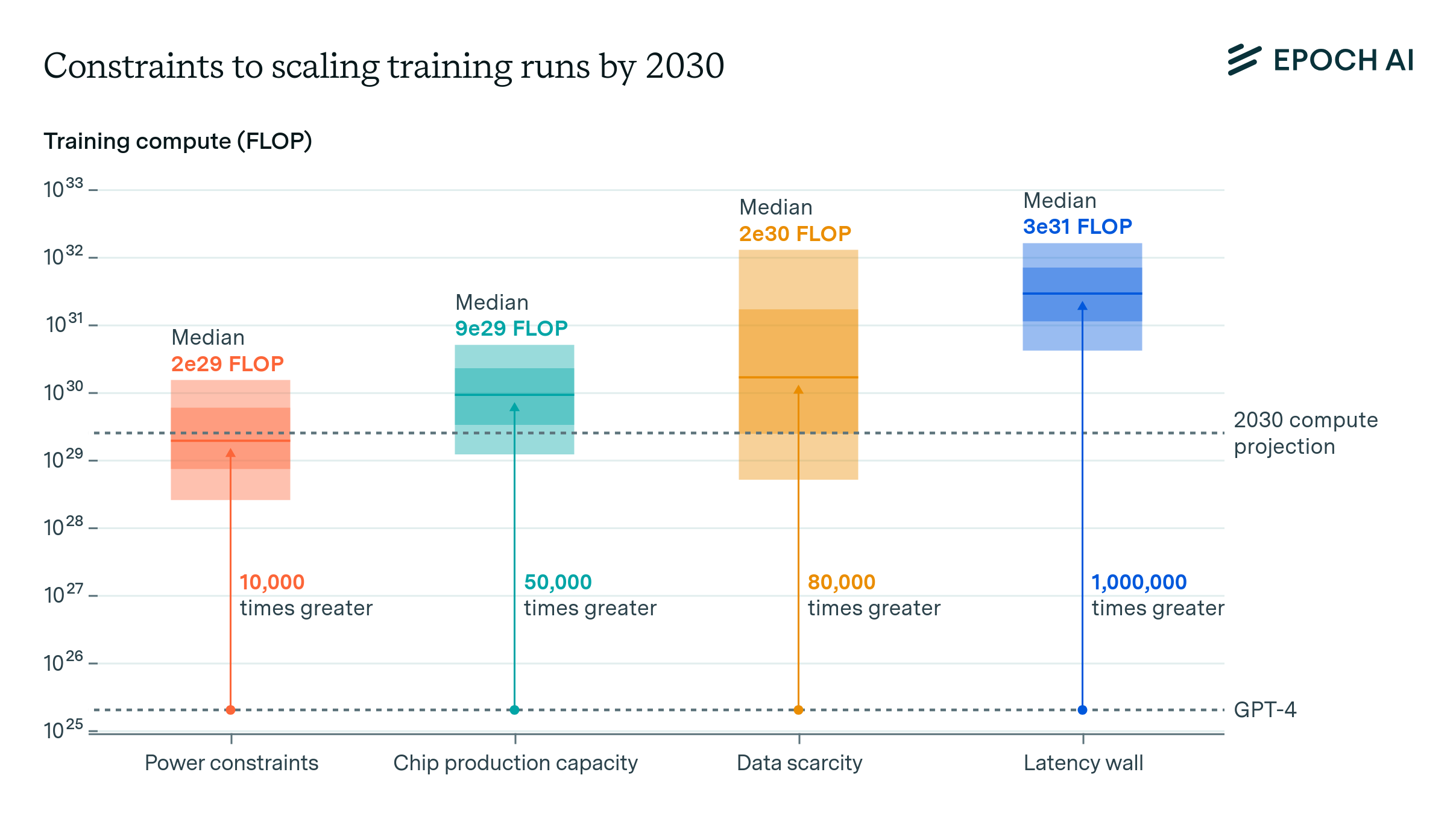
Figure 1: Estimates of the scale constraints imposed by the most important bottlenecks to scale. Each estimate is based on historical projections. The dark shaded box corresponds to an interquartile range and light shaded region to an 80% confidence interval. Click on the arrow to learn more.
NOTE:
- Key Insights from Figure 1:
- Power constraints (left): By 2030, AI training runs could reach 2e29 FLOP with power limitations being the most immediate constraint. The projection here suggests a 10,000-fold increase in computational power relative to GPT-4.
- Chip production capacity (second from the left): Constraints on chip manufacturing could allow training runs of up to 9e29 FLOP, which would be 50,000 times greater than GPT-4.
- Data scarcity (second from the right): The scarcity of high-quality data might cap training runs at around 2e30 FLOP, representing an 80,000-fold increase over current levels.
- Latency wall (right): Latency constraints, primarily in distributed systems, could allow training runs to reach 3e31 FLOP, a 1,000,000-fold increase over GPT-4's compute.
- Each bar represents the median estimate of the largest training run feasible by 2030 for each constraint, with shaded regions showing uncertainty ranges (interquartile and confidence intervals).
NOTE: Figure 2: Reported and planned total installed IT capacity of North American data centers, visualizing trends and projections of power growth for AI and non-AI data centers.
NOTE: Figure 3: Assumptions and estimates related to power supply scaling and training run sizes, illustrating the maximum feasible scale of AI training runs.
References
;