2003 ANeuralProbabilisticLanguageMod
- (Bengio et al., 2003a) ⇒ Yoshua Bengio, Réjean Ducharme, Pascal Vincent, and Christian Janvin. (2003). “A Neural Probabilistic Language Model.” In: The Journal of Machine Learning Research, 3.
Subject Headings: Distributional Word Representation, Neural Probabilistic Language Model.
Notes
Cited By
- Google Scholar: ~ 7,516 Citations.
- ACM DL: ~ 595 Citations.
2018
- https://towardsdatascience.com/3-silver-bullets-of-word-embedding-in-nlp-10fa8f50cc5a
- QUOTE: ... 12 years before Tomas et al. introduces Word2Vec, Bengio et al. published a paper (Bengio et al., 2003a) to tackle language modeling and it is the initial idea of word embedding. At that time, they named this process as “learning a distributed representation for words”.
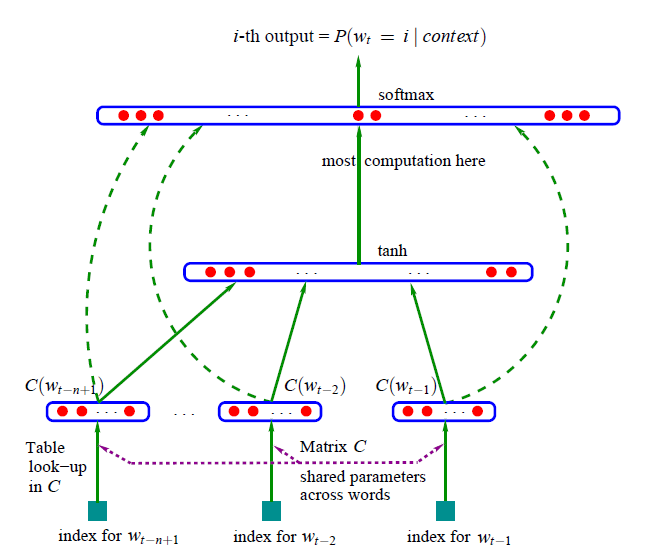
- QUOTE: ... 12 years before Tomas et al. introduces Word2Vec, Bengio et al. published a paper (Bengio et al., 2003a) to tackle language modeling and it is the initial idea of word embedding. At that time, they named this process as “learning a distributed representation for words”.
2013
- (Mikolov et al., 2013a) ⇒ Tomáš Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. (2013). “Efficient Estimation of Word Representations in Vector Space.” In: Proceedings of International Conference of Learning Representations Workshop.
- QUOTE: Representation of words as continuous vectors has a long history [10, 26, 8]. A very popular model architecture for estimating neural network language model (NNLM) was proposed in (Bengio et al., 2003a), where a feedforward neural network with a linear projection layer and a non-linear hidden layer was used to learn jointly the word vector representation and a statistical language model. This work has been followed by many others.
Quotes
Abstract
A goal of statistical language modeling is to learn the joint probability function of sequences of words in a language. This is intrinsically difficult because of the curse of dimensionality: a word sequence on which the model will be tested is likely to be different from all the word sequences seen during training. Traditional but very successful approaches based on n-grams obtain generalization by concatenating very short overlapping sequences seen in the training set. We propose to fight the curse of dimensionality by learning a distributed representation for words which allows each training sentence to inform the model about an exponential number of semantically neighboring sentences. The model learns simultaneously (1) a distributed representation for each word along with (2) the probability function for word sequences, expressed in terms of these representations. Generalization is obtained because a sequence of words that has never been seen before gets high probability if it is made of words that are similar (in the sense of having a nearby representation) to words forming an already seen sentence. Training such large models (with millions of parameters) within a reasonable time is itself a significant challenge. We report on experiments using neural networks for the probability function, showing on two text corpora that the proposed approach significantly improves on state-of-the-art n-gram models, and that the proposed approach allows to take advantage of longer contexts.
References
BibTeX
@article{2003_ANeuralProbabilisticLanguageMod,
author = {Yoshua Bengio and
Rejean Ducharme and
Pascal Vincent and
Christian Janvin},
title = {A Neural Probabilistic Language Model},
journal = {Journal of Machine Learning Research},
volume = {3},
pages = {1137--1155},
year = {2003},
url = {http://jmlr.org/papers/v3/bengio03a.html},
}
| Author | volume | Date Value | title | type | journal | titleUrl | doi | note | year | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2003 ANeuralProbabilisticLanguageMod | Yoshua Bengio Pascal Vincent Christian Janvin Réjean Ducharme | A Neural Probabilistic Language Model | 2003 |