Information Extraction from Text System
(Redirected from natural language processing system for information extraction)
Jump to navigation
Jump to search
A Information Extraction from Text System is a information extraction system that can solve an Information Extraction from Text Task by implementing an IE from text algorithm.
- Context:
- It usually consists of the following sub-systems:
- Sentence Segmentation System - extracts sentences (a list of strings);
- Word Tokenization System - extracts tokenized sentences (a list of tokens);
- Part-of-Speech Tagging System - extracts post-tagged sentences (a list of tuples);
- Entity Extraction System - extracts chunked sentences (a list of parse tree),
- Relation Extraction System -extracts relation between phrases or words (a list of tuples).
- It can range from being an Open IE from Text System to being a Closed IE from Text System (such as ontology-based IE system).
- It usually consists of the following sub-systems:
- Example(s):
- a Web Information Extraction System (if it extracts information from the web).
- an Ontology-based IE System.
- a Terminology Extraction System.
- DeepDive System (~2014 to present).
- ANNIE System which is part of the GATE System
- TextRunner System,
- TextBlob System,
- KnowItAll Web IE System.
- Opine System, for Marketable Product Information.
- Crystal System (~1995)
- FASTUS System (~1993).
- RULIE System (~2011).
- NELL System (~2010-?).
- …
- Counter-Example(s):
- See: IE from Audio System, Semantic Relation Recognition System, Pattern Extractor, Natural Language Processing System, Sentence Segmentation System, Entity Detection System, Tokenization System, Part-Of-Speech (POS) Tagging System.
References
2009
- (Bird et al., 2009) ⇒ Steven Bird, Ewan Klein, and Edward Loper. (2009). "Extracting Information from Text". In:“Natural Language Processing with Python." O'Reilly Media. ISBN:9780596555719 (Chapter 7).
- QUOTE: Figure 7-1 shows the architecture for a simple information extraction system. It begins by processing a document using several of the procedures discussed in Chapters 3 and 5: first, the raw text of the document is split into sentences using a sentence segmenter, and each sentence is further subdivided into words using a tokenizer. Next, each sentence is tagged with part-of-speech tags, which will prove very helpful in the next step, named entity recognition. In this step, we search for mentions of potentially interesting entities in each sentence. Finally, we use relation recognition to search for likely relations between different entities in the text.
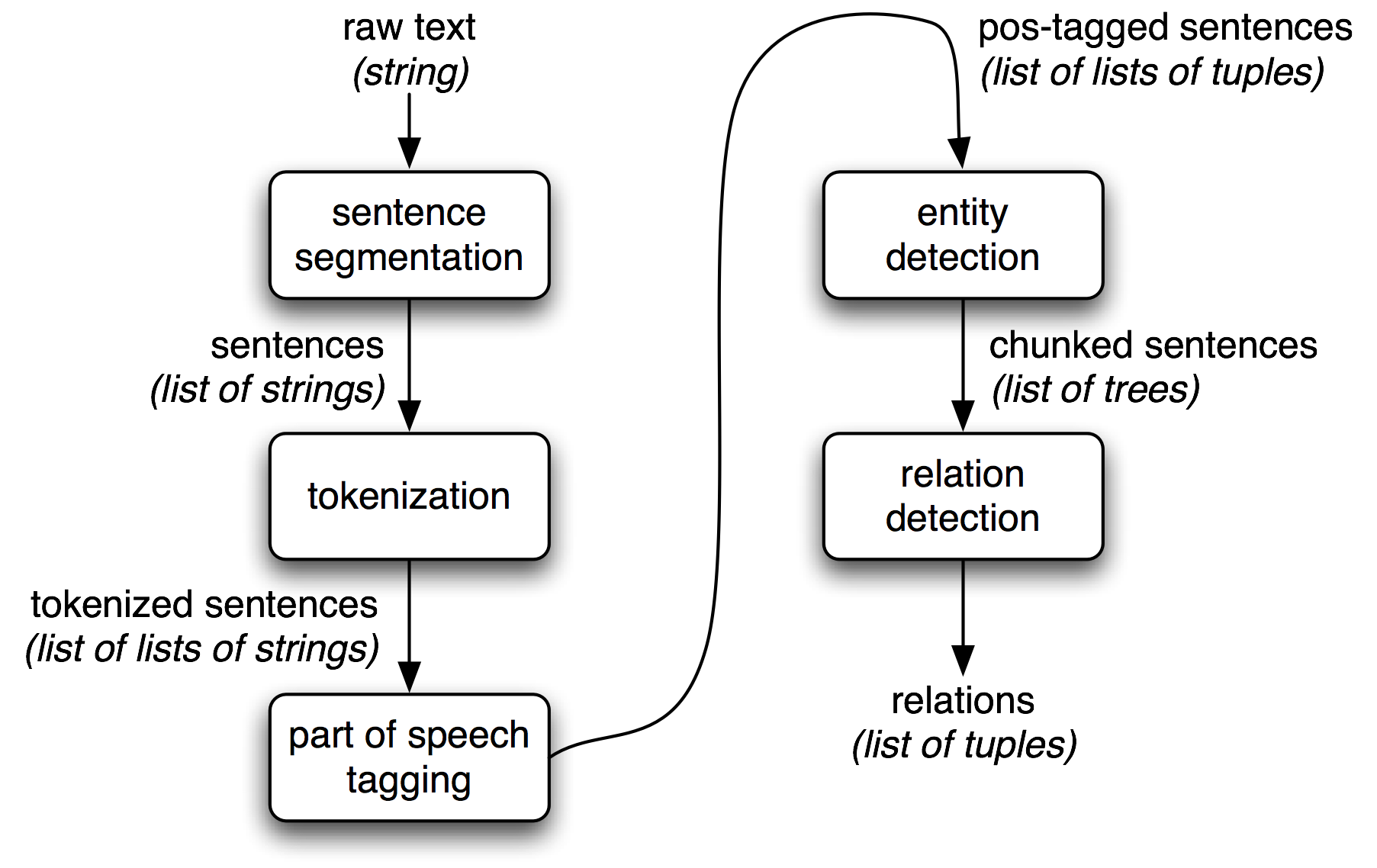
Figure 7-1. Simple pipeline architecture for an information extraction system. This system takes the raw text of a document as its input, and generates a list of (entity, relation, entity) tuples as its output. For example, given a document that indicates that the company Georgia-Pacific is located in Atlanta, it might generate the tuple (
[ORG: 'Georgia-Pacific']'in'[LOC: 'Atlanta']).
- QUOTE: Figure 7-1 shows the architecture for a simple information extraction system. It begins by processing a document using several of the procedures discussed in Chapters 3 and 5: first, the raw text of the document is split into sentences using a sentence segmenter, and each sentence is further subdivided into words using a tokenizer. Next, each sentence is tagged with part-of-speech tags, which will prove very helpful in the next step, named entity recognition. In this step, we search for mentions of potentially interesting entities in each sentence. Finally, we use relation recognition to search for likely relations between different entities in the text.
2006
- (BioCreative, 2006) ⇒ http://biocreative.sourceforge.net/biocreative_glossary.html
- Information extraction (IE): IE systems perform natural language text analysis in order to identify information related to pre-defined types of entities (e.g. genes or proteins), relationships, facts or events.
2002
- (Cunningham et al., 2002) ⇒ Hamish Cunningham, Diana Maynard, Kalina Bontcheva, and Valentin Tablan. (2001). “GATE: A Framework and Graphical Development Environment for Robust NLP Tools and Applications.” In: Proceedings of the 40th Anniversary Meeting of the Association for Computational Linguistics (ACL 2002).
1993
- Douglas E. Appelt, Jerry R. Hobbs, John Bear, David Israel, and Mabry Tyson. (1993). “FASTUS: A Finite-State Processor for Information Extraction From Real-World Text.” In: Proceedings of the Thirteenth International Joint Conference on Artificial Intelligence (IJCAI-93).