Entity Extraction System
Jump to navigation
Jump to search
An Entity Extraction System is an Information Extraction System that can extract a list of entities from a post-tagged or raw text.
- Context:
- It can solve an Entity Extraction Task by implementing Entity Extraction Alogrithms.
- It can range being an Unstructured Data Entity Extraction System, to be Semistructured Data Entity Extraction System, to being Structured Data Entity Extraction System,
- Example(s):
- a Text Chunking System such as:
- a Named Entity Recognition System.
- …
- Counter-Example(s):
- a Text Chinking System,
- a Sentence Segmentation System - extracts sentences (a list of strings);
- a Word Tokenization System - extracts tokenized sentences (a list of tokens);
- a Part-of-Speech Tagging System - extracts post-tagged sentences (a list of tuples);
- a Relation Extraction System -extracts relation between phrases or words (a list of tuples).
- See: Natural Language Processing System, Noun Compound Bracketing Task, Training Classifier-Based Chunkers.
References
2009
- (Bird et al., 2009) ⇒ Steven Bird, Ewan Klein, and Edward Loper. (2009). "Extracting Information from Text". In:“Natural Language Processing with Python." O'Reilly Media. ISBN:9780596555719 (Chapter 7).
- QUOTE: Figure 7-1 shows the architecture for a simple information extraction system. It begins by processing a document using several of the procedures discussed in Chapters 3 and 5: first, the raw text of the document is split into sentences using a sentence segmenter, and each sentence is further subdivided into words using a tokenizer. Next, each sentence is tagged with part-of-speech tags, which will prove very helpful in the next step, named entity recognition. In this step, we search for mentions of potentially interesting entities in each sentence. Finally, we use relation recognition to search for likely relations between different entities in the text.
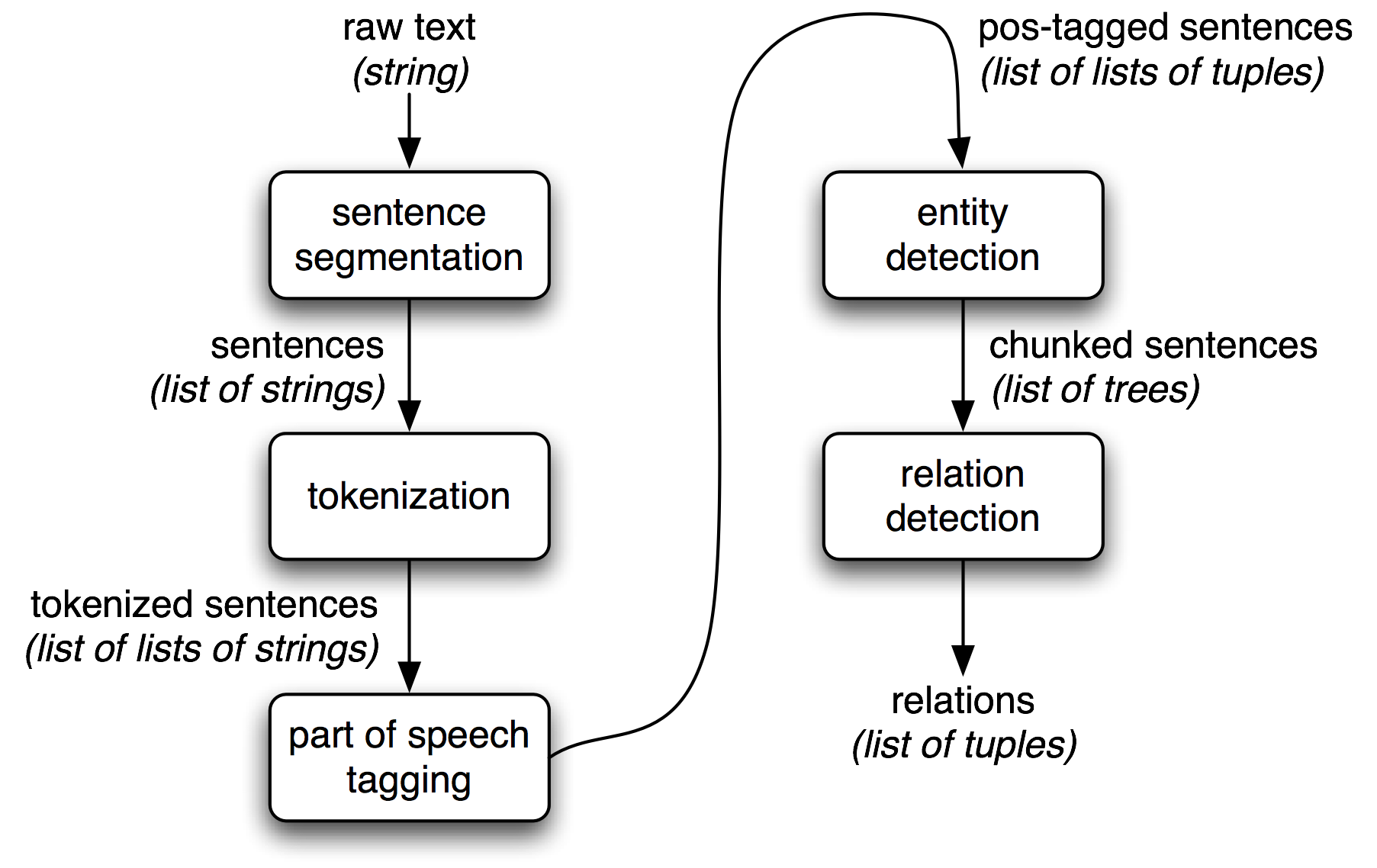
Figure 7-1. Simple pipeline architecture for an information extraction system. This system takes the raw text of a document as its input, and generates a list of (entity, relation, entity) tuples as its output. For example, given a document that indicates that the company Georgia-Pacific is located in Atlanta, it might generate the tuple (
[ORG: 'Georgia-Pacific']'in'[LOC: 'Atlanta']).
- QUOTE: Figure 7-1 shows the architecture for a simple information extraction system. It begins by processing a document using several of the procedures discussed in Chapters 3 and 5: first, the raw text of the document is split into sentences using a sentence segmenter, and each sentence is further subdivided into words using a tokenizer. Next, each sentence is tagged with part-of-speech tags, which will prove very helpful in the next step, named entity recognition. In this step, we search for mentions of potentially interesting entities in each sentence. Finally, we use relation recognition to search for likely relations between different entities in the text.