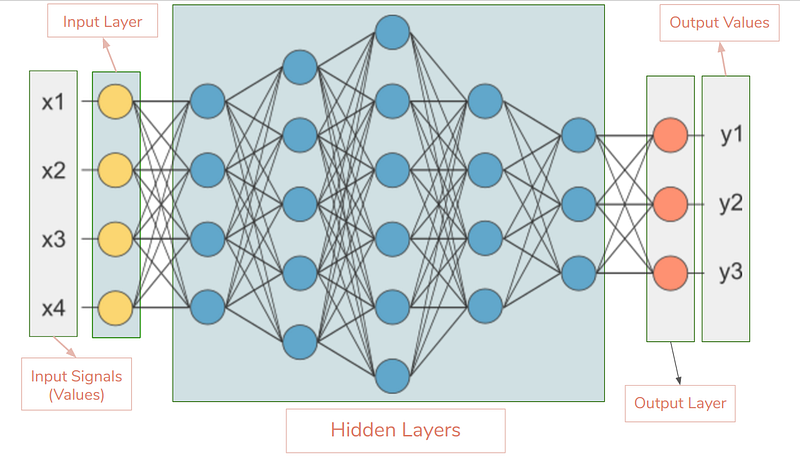
Multi Hidden-Layer (Deep) Neural Network
A Multi Hidden-Layer (Deep) Neural Network is an artificial neural network with more than one hidden network layer.
- Context:
- It can (typically) perform automated Feature Engineering (which can learn high-dimensional data representation with multiple levels of abstraction).
- It can (typically) be trained by a Multi-Layer Network Training System (that implements a multi-layer network training algorithm to solve a multi-layer network training task).
- It can range from being a Trained Multi Hidden-Layer ANN to being an Multi Hidden-Layer ANN Architecture.
- It can range from being a Shallow Multi Hidden-Layer ANN, to being a Medium-Depth ANN to being a Very-Deep ANN).
- It can range from being a Multi-Layer Feedforward Neural Network to being a Multi-Layer Recurrent Neural Network.
- It can range from being a Logistic-based Multi-Layer Neural Network, to being a Hyperbolic Tangent-based Multi-Layer Neural Network, to being a Rectifier-based Multi-Layer Neural Network, to being a Hybrid Activation Multi-Layer ANN, based on its neuron activation function.
- It can range from being a Small Deep NNet to being a Medium-sized Deep NNet to being a Large Deep NNet.
- It can be a Multi-Layer Neural Network Classifier, to being a Multi-Layer Neural Network Ranker, to being a Multi-Layer Neural Network Estimator.
- It can be a Regularized Multi Hidden-Layer Neural Network.
- Examples(s):
- a Fully-Connected Multi-layer ANN, such as
- a Convolutional ANN.
- a Recurrent ANN.
- a Deep Belief Network.
- a Recursive Neural Network.
- a Deep Bayesian ANN.
- a Dynamic Coattention Network.
- a Deep Boltzmann Machine.
- a Stacked (Denoising) Auto-Encoder.
- a Deep Stacking Network.
- a Tensor Deep Stacking Networks (T-DSN).
- a Spike-and-Slab RBM (ssRBM).
- a Compound Hierarchical-Deep Model.
- a Deep Coding Network.
- a Deep Kernel Machine.
- …
- a Fully-Connected Multi-layer ANN, such as
- Counter-Example(s):
- See: Multi-layer Perceptron, Cross Entropy, Feedforward Neural Network, Recurrent Neural Network, Convolutional Neural Network, Discriminative Model, Non-Linear Transform.



References
2017
- https://blog.keras.io/the-limitations-of-deep-learning.html
- QUOTE: … In deep learning, everything is a vector, i.e. everything is a point in a geometric space. Model inputs (it could be text, images, etc) and targets are first “vectorized", i.e. turned into some initial input vector space and target vector space. Each layer in a deep learning model operates one simple geometric transformation on the data that goes through it. Together, the chain of layers of the model forms one very complex geometric transformation, broken down into a series of simple ones. This complex transformation attempts to maps the input space to the target space, one point at a time. This transformation is parametrized by the weights of the layers, which are iteratively updated based on how well the model is currently performing. A key characteristic of this geometric transformation is that it must be differentiable, which is required in order for us to be able to learn its parameters via gradient descent. Intuitively, this means that the geometric morphing from inputs to outputs must be smooth and continuous — a significant constraint.
The whole process of applying this complex geometric transformation to the input data can be visualized in 3D by imagining a person trying to uncrumple a paper ball: the crumpled paper ball is the manifold of the input data that the model starts with. Each movement operated by the person on the paper ball is similar to a simple geometric transformation operated by one layer. The full uncrumpling gesture sequence is the complex transformation of the entire model. Deep learning models are mathematical machines for uncrumpling complicated manifolds of high-dimensional data.
That's the magic of deep learning: turning meaning into vectors, into geometric spaces, then incrementally learning complex geometric transformations that map one space to another. All you need are spaces of sufficiently high dimensionality in order to capture the full scope of the relationships found in the original data. …
… deep learning model is "just" a chain of simple, continuous geometric transformations mapping one vector space into another. All it can do is map one data manifold X into another manifold Y, assuming the existence of a learnable continuous transform from X to Y, and the availability of a dense sampling of X:Y to use as training data. So even though a deep learning model can be interpreted as a kind of program, inversely most programs cannot be expressed as deep learning models …
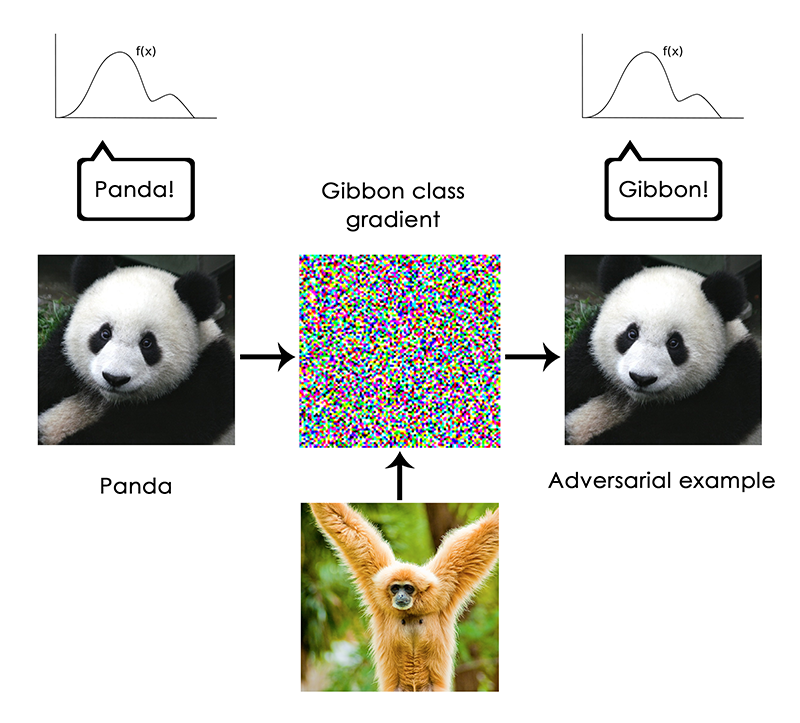
- QUOTE: … In deep learning, everything is a vector, i.e. everything is a point in a geometric space. Model inputs (it could be text, images, etc) and targets are first “vectorized", i.e. turned into some initial input vector space and target vector space. Each layer in a deep learning model operates one simple geometric transformation on the data that goes through it. Together, the chain of layers of the model forms one very complex geometric transformation, broken down into a series of simple ones. This complex transformation attempts to maps the input space to the target space, one point at a time. This transformation is parametrized by the weights of the layers, which are iteratively updated based on how well the model is currently performing. A key characteristic of this geometric transformation is that it must be differentiable, which is required in order for us to be able to learn its parameters via gradient descent. Intuitively, this means that the geometric morphing from inputs to outputs must be smooth and continuous — a significant constraint.
2017a
- (Schmidhuber, 2017) ⇒ Schmidhuber, J. (2017) "Deep Learning". In: Sammut, C., Webb, G.I. (eds) "Encyclopedia of Machine Learning and Data Mining". Springer, Boston, MA
- QUOTE: Deep learning artificial neural networks have won numerous contests in pattern recognition and machine learning. They are now widely used by the worlds most valuable public companies. I review the most popular algorithms for feedforward and recurrent networks and their history (...)
A standard NN consists of many simple, connected processors called units, each producing a sequence of real-valued activations. Input units get activated through sensors perceiving the environment, other units through connections with real-valued weights from previously active units. Some units may influence the environment by triggering actions. Learning or credit assignment is about finding weights that make the NN exhibit desired behavior, such as controlling a robot. Depending on the problem and how the units are connected, such behavior may require long causal chains of computational stages, where each stage transforms (often in a nonlinear way) the aggregate activation of the network. Deep learning in NNs is about accurately assigning credit across many such stages.
In a sense, sequence-processing recurrent NNs (RNNs) are the ultimate NNs, because they are general computers (an RNN can emulate the circuits of a microchip). In fully connected RNNs, all units have connections to all non-input units. Unlike feedforward NNs, RNNs can implement while loops, recursion, etc. The program of an RNN is its weight matrix. RNNs can learn programs that mix sequential and parallel information processing in a natural and efficient way.
To measure whether credit assignment in a given NN application is of the deep or shallow type, we consider the length of the corresponding credit assignment paths, which are chains of possibly causal connections between subsequent unit activations, e.g., from input units through hidden units to output units in feedforward NNs (FNNs) without feedback connections or through transformations over time in RNNs. FNNs with fixed topology have a problem-independent maximal problem depth bounded by the number of layers of units. RNNs, the deepest of all NNs, may learn to solve problems of potentially unlimited depth, for example, by learning to store in their activation-based “short-term memory” representations of certain important previous observations for arbitrary time intervals.
- QUOTE: Deep learning artificial neural networks have won numerous contests in pattern recognition and machine learning. They are now widely used by the worlds most valuable public companies. I review the most popular algorithms for feedforward and recurrent networks and their history (...)
2017b
- (Wikipedia, 2017) ⇒ https://en.wikipedia.org/wiki/Deep_learning#Deep_neural_networks Retrieved:2017-12-17.
- A deep neural network (DNN) is an ANN with multiple hidden layers between the input and output layers. Similar to shallow ANNs, DNNs can model complex non-linear relationships. DNN architectures generate compositional models where the object is expressed as a layered composition of primitives. The extra layers enable composition of features from lower layers, potentially modeling complex data with fewer units than a similarly performing shallow network. Deep architectures include many variants of a few basic approaches. Each architecture has found success in specific domains. It is not always possible to compare the performance of multiple architectures, unless they have been evaluated on the same data sets. DNNs are typically feedforward networks in which data flows from the input layer to the output layer without looping back. Recurrent neural networks (RNNs), in which data can flow in any direction, are used for applications such as language modeling. [1] Dan Gillick, Cliff Brunk, Oriol Vinyals, Amarnag Subramanya (2015). Multilingual Language Processing From Bytes. arXiv </ref> Long short-term memory is particularly effective for this use. Convolutional deep neural networks (CNNs) are used in computer vision. CNNs also have been applied to acoustic modeling for automatic speech recognition (ASR).
2017c
- (DL4J, 2017) ⇒ "Key Concepts of Deep Neural Networks" https://deeplearning4j.org/neuralnet-overview#concept Retrieved: 2017-12-17
- QUOTE: Deep-learning networks are distinguished from the more commonplace single-hidden-layer neural networks by their depth; that is, the number of node layers through which data passes in a multistep process of pattern recognition.
Traditional machine learning relies on shallow nets, composed of one input and one output layer, and at most one hidden layer in between. More than three layers (including input and output) qualifies as “deep” learning. So deep is a strictly defined, technical term that means more than one hidden layer.
In deep-learning networks, each layer of nodes trains on a distinct set of features based on the previous layer’s output. The further you advance into the neural net, the more complex the features your nodes can recognize, since they aggregate and recombine features from the previous layer.
This is known as feature hierarchy, and it is a hierarchy of increasing complexity and abstraction. It makes deep-learning networks capable of handling very large, high-dimensional data sets with billions of parameters that pass through nonlinear functions.
Above all, these nets are capable of discovering latent structures within unlabeled, unstructured data, which is the vast majority of data in the world. Another word for unstructured data is raw media; i.e. pictures, texts, video and audio recordings. Therefore, one of the problems deep learning solves best is in processing and clustering the world’s raw, unlabeled media, discerning similarities and anomalies in data that no human has organized in a relational database or ever put a name to.
(...)
Deep-learning networks end in an output layer: a logistic, or softmax, classifier that assigns a likelihood to a particular outcome or label. We call that predictive, but it is predictive in a broad sense. Given raw data in the form of an image, a deep-learning network may decide, for example, that the input data is 90 percent likely to represent a person.
- QUOTE: Deep-learning networks are distinguished from the more commonplace single-hidden-layer neural networks by their depth; that is, the number of node layers through which data passes in a multistep process of pattern recognition.
2017d
- (Sze et al., 2017) ⇒ Sze, V., Chen, Y. H., Yang, T. J., & Emer, J. (2017). Efficient processing of deep neural networks: A tutorial and survey. arXiv preprint arXiv:1703.09039.
- ABSTRACT: Deep neural networks (DNNs) are currently widely used for many artificial intelligence (AI) applications including computer vision, speech recognition, and robotics. While DNNs deliver state-of-the-art accuracy on many AI tasks, it comes at the cost of high computational complexity. Accordingly, techniques that enable efficient processing of DNNs to improve energy efficiency and throughput without sacrificing application accuracy or increasing hardware cost are critical to the wide deployment of DNNs in AI systems.
This article aims to provide a comprehensive tutorial and survey about the recent advances towards the goal of enabling efficient processing of DNNs. Specifically, it will provide an overview of DNNs, discuss various hardware platforms and architectures that support DNNs, and highlight key trends in reducing the computation cost of DNNs either solely via hardware design changes or via joint hardware design and DNN algorithm changes. It will also summarize various development resources that enable researchers and practitioners to quickly get started in this field, and highlight important benchmarking metrics and design considerations that should be used for evaluating the rapidly growing number of DNN hardware designs, optionally including algorithmic co-designs, being proposed in academia and industry.
The reader will take away the following concepts from this article: understand the key design considerations for DNNs; be able to evaluate different DNN hardware implementations with benchmarks and comparison metrics; understand the trade-offs between various hardware architectures and platforms; be able to evaluate the utility of various DNN design techniques for efficient processing; and understand recent implementation trends and opportunities.
- ABSTRACT: Deep neural networks (DNNs) are currently widely used for many artificial intelligence (AI) applications including computer vision, speech recognition, and robotics. While DNNs deliver state-of-the-art accuracy on many AI tasks, it comes at the cost of high computational complexity. Accordingly, techniques that enable efficient processing of DNNs to improve energy efficiency and throughput without sacrificing application accuracy or increasing hardware cost are critical to the wide deployment of DNNs in AI systems.
2015
- http://cacm.acm.org/magazines/2015/7/188737-growing-pains-for-deep-learning/fulltext
- QUOTE: massively missing data … the use of layers of Gaussian processes, which use probability theory, in place of neural networks, to provide effective learning on smaller datasets, and for applications in which the neural networks do not perform well, such as data that is interconnected across many different databases, which is the case in healthcare. Because data may not be present in certain databases for a given candidate, a probabilistic model can deal with the situation better than traditional machine-learning techniques. …
"But I would say that what we would like mostly is to have a better understanding of why deep learning works."
- QUOTE: massively missing data … the use of layers of Gaussian processes, which use probability theory, in place of neural networks, to provide effective learning on smaller datasets, and for applications in which the neural networks do not perform well, such as data that is interconnected across many different databases, which is the case in healthcare. Because data may not be present in certain databases for a given candidate, a probabilistic model can deal with the situation better than traditional machine-learning techniques. …
2015
- (Schmidhuber, 2015) ⇒ Jürgen Schmidhuber. (2015). “Deep Learning in Neural Networks: An Overview.” In: Neural Networks, 61.
- QUOTE: In recent years, deep artificial neural networks (including recurrent ones) have won numerous contests in pattern recognition and machine learning.
2006
- (Hinton et al., 2006) ⇒ Geoffrey E. Hinton, Simon Osindero, and Yee-Whye Teh. (2006). “A Fast Learning Algorithm for Deep Belief Nets.” In: Neural Computation Journal, 18(7). doi:10.1162/neco.2006.18.7.1527
2005
- (Golda, 2005) ⇒ Adam Golda (2005). "Introduction to neural networks"
- QUOTE: There are different types of neural networks, which can be distinguished on the basis of their structure and directions of signal flow. Each kind of neural network has its own method of training. Generally, neural networks may be differentiated as follows
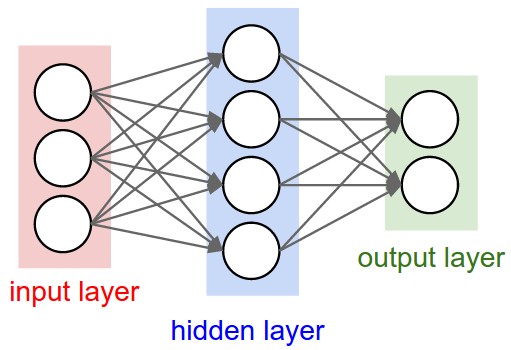
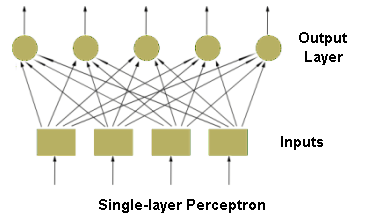
- Feedforward neural networks, which typical example is one-layer perceptron (see figure of Single-layer perceptron), consist of neurons set in layers. The information flow has one direction. Neurons from a layer are connected only with the neurons from the preceding layer. The multi-layer networks usually consist of input, hidden (one or more), and output layers. Such system may be treated as non-linear function approximation block: [math]\displaystyle{ y = f(u) }[/math].
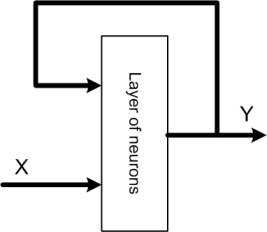
Recurrent neural networks. Such networks have feedback loops (at least one) output signals of a layer are connected to its inputs. It causes dynamic effects during network work. Input signals of layer consist of input and output states (from the previous step) of that layer. The structure of recurrent network depicts the below figure.
Cellular networks. In this type of neural networks neurons are arranged in a lattice. The connections (usually non-linear) may appear between the closest neurons. The typical example of such networks is Kohonen Self-Organising-Map.
 .
.
- Feedforward neural networks, which typical example is one-layer perceptron (see figure of Single-layer perceptron), consist of neurons set in layers. The information flow has one direction. Neurons from a layer are connected only with the neurons from the preceding layer. The multi-layer networks usually consist of input, hidden (one or more), and output layers. Such system may be treated as non-linear function approximation block: [math]\displaystyle{ y = f(u) }[/math].
{kind=link}
- ↑ Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, Yonghui Wu (2016). Exploring the Limits of Language Modeling.arXiv