Transformer-based Deep Neural Network (DNN) Model
A Transformer-based Deep Neural Network (DNN) Model is an sequence-to-* neural network composed of transformer blocks.
- Context:
- It can (typically) be trained by a Transformer-based Neural Network Training System (that solve transformer-based neural network training tasks).
- It can (often) reference a Transformer Model Architecture.
- It can (often) be represented in a Transformer-based Model Framework.
- ...
- It can range from being a Custom Transformer-based Neural Network to being a Pretrained Transformer-based Neural Network.
- It can range from being an Encoder-Decoder Transformer Model, to being an Encoder-Only Transformer Model, to being a Decoder-Only Transformer Model.
- with an Encoder Network, with sublayer's comprised of a multi-head self-attention and a feed-forward neural network.
- with a Decoder Network, with sublayers, two of which are similar to the encoder (multihead self-attention and feed-forward), while the third sublayer carries out multi-head attention on the encoder’s outputs.
- It can range from being a Vanilla Transformer DNN to being a Transformer-XL DNN.llions of parameters.
- It can range from being a Small-Scale Transformer-based Model (1M-100M parameters) to being an Large-Scale Transformer-based Model (>100M parameters), depending on its model architecture.
- ...
- It can have an Input Vector that is first transformed into three different vectors: the value vector v, the key vector k and the query vector q.
- It can be applied to Sequence Learning Tasks.
- It can receive a segment of tokens with an Attention Modules/Attention Head (e.g. K-Q-V attention).
- …
- Example(s):
- Pretrained Transformer-based Models, such as:
- a Pretrained BERT Model (BERT model matching a BERT architecture).
- a Generative Pre-trained Transformer (GPT) model pre-trained on large text corpora for generative tasks.
- a T5 (Text-To-Text Transfer Transformer) model converting all NLP problems into a text-to-text format.
- an Generative Pre-trained Transformer Network (Radford et al., 2018).
- Custom and Specialized Transformer Models, such as:
- a Transformer-XL model with segment-level recurrence and relative positional encoding.
- a Vision Transformer (ViT) model applying transformer architecture to image recognition tasks.
- a DETR (Detection Transformer) model utilizing transformers for object detection tasks.
- a Crowd Transformer Network (Ranjan et al., 2019).
- Autoregressive Transformer-based Models, such as:
- an Autoregressive Transformer-based Model, such as: Transformer-based LLM.
- a model developed in Vaswani et al. (2017).
- Transformer-based Models Across Domains, such as:
- Transformer-based Language Model, such as:
- a ... model (based on Al-Rfou et al., 2017).
- a BERT model (based on a BERT architecture).
- Transformer-based Vision Models, such as:
- Vision Transformer (ViT) (based on the standard Transformer architecture)
- DETR (Detection Transformer) (based on the Transformer architecture with additional object detection capabilities).
- Transformer-based Language Model, such as:
- …
- Pretrained Transformer-based Models, such as:
- Counter-Example(s):
- Convolutional Neural Network (CNN), which uses convolutional layers to process spatial hierarchies in images.
- Recurrent Neural Network (RNN), which uses recurrent connections to process sequential data.
- Long Short-Term Memory (LSTM), a type of RNN with memory cells to capture long-term dependencies.
- Bidirectional Recurrent Neural Network with Attention Mechanism, which uses attention mechanisms in a recurrent architecture.
- Stacked Autoencoding Neural Network, which uses autoencoders stacked in multiple layers for unsupervised learning.
- Neural GPU (Kaiser & Sutskever, 2016), which uses grid-like structures for computations.
- See: Attention Mechanism, Attention Weight Matrix, Positional Encoding, Attention Head, Memory Augmented Neural Network, Sequential Transfer Learning System, Neural Machine Translation Network.
References
2024
- "No Priors Ep. 80 | With Andrej Karpathy from OpenAI and Tesla." YouTube
- NOTES:
- The transformer model is considered a "differentiable computer" that excels in scalability, allowing for efficient training with large datasets through backpropagation.
- Key innovations in transformers, such as residual connections, layer normalization, and attention mechanisms, have contributed to their success and generality in various tasks.
- The current bottleneck in AI is no longer the architecture but rather the quality of datasets and the design of loss functions, as the transformer architecture is now considered mature.
- Recent transformer innovations, such as RoPE positional encodings, are relatively minor, with most advancements focusing on data and fine-tuning strategies rather than the model's core structure.
- NOTES:
2021
- (Wikipedia, 2021) ⇒ https://en.wikipedia.org/wiki/Transformer_(machine_learning_model) Retrieved:2021-5-24.
- A transformer is a deep learning model that adopts the mechanism of attention, weighing the influence of different parts of the input data. It is used primarily in the field of natural language processing (NLP). It also has applications in tasks such as video understanding. [1] Like recurrent neural networks (RNNs), transformers are designed to handle sequential input data, such as natural language, for tasks such as translation and text summarization. However, unlike RNNs, transformers do not require that the sequential data be processed in order. Rather, the attention operation provides context for any position in the input sequence. For example, if the input data is a natural language sentence, the transformer does not need to process the beginning of the sentence before the end. Rather, it identifies the context that confers meaning to a word in the sentence. Due to this feature, the transformer allows for much more parallelization than RNNs and therefore reduces training times. Transformers have rapidly become the model of choice for NLP problems, replacing older RNN models such as long short-term memory (LSTM). Since the transformer model facilitates more parallelization during training, it has enabled training on larger datasets than was once possible. This led to the development of pretrained systems such as BERT (Bidirectional Encoder Representations from transformers) and GPT (Generative Pre-trained transformer), which have been trained with large language datasets, such as Wikipedia Corpus and Common Crawl, and can be fine-tuned to specific tasks.
2020
- (Wikipedia, 2020) ⇒ https://en.wikipedia.org/wiki/Transformer_(machine_learning_model) Retrieved:2020-9-15.
- The Transformer is a deep learning model introduced in 2017, used primarily in the field of natural language processing (NLP). Polosukhin, Illia; Kaiser, Lukasz; Gomez, Aidan N.; Jones, Llion; Uszkoreit, Jakob; Parmar, Niki; Shazeer, Noam; Vaswani, Ashish (2017-06-12). “Attention Is All You Need". arXiv:1706.03762.</ref>
Like recurrent neural networks (RNNs), Transformers are designed to handle sequential data, such as natural language, for tasks such as translation and text summarization. However, unlike RNNs, Transformers do not require that the sequential data be processed in order. For example, if the input data is a natural language sentence, the Transformer does not need to process the beginning of it before the end. Due to this feature, the Transformer allows for much more parallelization than RNNs and therefore reduced training times.
Since their introduction, Transformers have become the model of choice for tackling many problems in NLP, replacing older recurrent neural network models such as the long short-term memory (LSTM). Since the Transformer model facilitates more parallelization during training, it has enabled training on larger datasets than was possible before it was introduced. This has led to the development of pretrained systems such as BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer), which have been trained with huge general language datasets, and can be fine-tuned to specific language tasks. "Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing". Google AI Blog. Retrieved 2019-08-25.</ref> "Better Language Models and Their Implications". OpenAI. 2019-02-14. Retrieved 2019-08-25.</ref>
- The Transformer is a deep learning model introduced in 2017, used primarily in the field of natural language processing (NLP). Polosukhin, Illia; Kaiser, Lukasz; Gomez, Aidan N.; Jones, Llion; Uszkoreit, Jakob; Parmar, Niki; Shazeer, Noam; Vaswani, Ashish (2017-06-12). “Attention Is All You Need". arXiv:1706.03762.</ref>
2020
- https://jalammar.github.io/illustrated-transformer/
- The Transformer – a model that uses attention to boost the speed with which these models can be trained.

2019b
- (Horev, 2019) ⇒ Rani Horev (Jan, 2017). "Transformer-XL Explained: Combining Transformers and RNNs into a State-of-the-art Language Model". In: Medium -Towards Data Science Blog.
- QUOTE: ... Transformers, invented in 2017, introduced a new approach — attention modules. Instead of processing tokens one by one, attention modules receive a segment of tokens and learn the dependencies between all of them at once using three learned weight matrices — Query, Key and Value — that form an Attention Head. The Transformer network consists of multiple layers, each with several Attention Heads (and additional layers), used to learn different relationships between tokens.
As in many NLP models, the input tokens are first embedded into vectors. Due to the concurrent processing in the attention module, the model also needs to add information about the order of the tokens, a step named Positional Encoding, that helps the network learn their position. In general, this step is done with a sinusoidal function that generates a vector according to the token’s position, without any learned parameters.
An example of a single Attention Head on a single token (E1).
Its output is calculated using its Query vector, and the Key and Value vectors of all tokens (In the chart we show only one additional token E2)
— The Query and the Key define the weight of each token, and the output is the weighted sum of all Value vectors.
- QUOTE: ... Transformers, invented in 2017, introduced a new approach — attention modules. Instead of processing tokens one by one, attention modules receive a segment of tokens and learn the dependencies between all of them at once using three learned weight matrices — Query, Key and Value — that form an Attention Head. The Transformer network consists of multiple layers, each with several Attention Heads (and additional layers), used to learn different relationships between tokens.

2018a
- (Gouws, 2018) ⇒ Stephan Gouws (August, 2018) ⇒ "Moving Beyond Translation with the Universal Transformer". In: Google AI Blog
- QUOTE: ... Last year we released the Transformer, a new machine learning model that showed remarkable success over existing algorithms for machine translation and other language understanding tasks. Before the Transformer, most neural network based approaches to machine translation relied on recurrent neural networks (RNNs) which operate sequentially (e.g. translating words in a sentence one-after-the-other) using recurrence (i.e. the output of each step feeds into the next). While RNNs are very powerful at modeling sequences, their sequential nature means that they are quite slow to train, as longer sentences need more processing steps, and their recurrent structure also makes them notoriously difficult to train properly. In contrast to RNN-based approaches, the Transformer used no recurrence, instead processing all words or symbols in the sequence in parallel while making use of a self-attention mechanism to incorporate context from words farther away. By processing all words in parallel and letting each word attend to other words in the sentence over multiple processing steps, the Transformer was much faster to train than recurrent models. Remarkably, it also yielded much better translation results than RNNs. However, on smaller and more structured language understanding tasks, or even simple algorithmic tasks such as copying a string (e.g. to transform an input of “abc” to “abcabc”), the Transformer does not perform very well. In contrast, models that perform well on these tasks, like the Neural GPU and Neural Turing Machine, fail on large-scale language understanding tasks like translation. In “Universal Transformers” we extend the standard Transformer to be computationally universal (Turing complete) using a novel, efficient flavor of parallel-in-time recurrence which yields stronger results across a wider range of tasks. We built on the parallel structure of the Transformer to retain its fast training speed, but we replaced the Transformer’s fixed stack of different transformation functions with several applications of a single, parallel-in-time recurrent transformation function (i.e. the same learned transformation function is applied to all symbols in parallel over multiple processing steps, where the output of each step feeds into the next). Crucially, where an RNN processes a sequence symbol-by-symbol (left to right), the Universal Transformer processes all symbols at the same time (like the Transformer), but then refines its interpretation of every symbol in parallel over a variable number of recurrent processing steps using self-attention. This parallel-in-time recurrence mechanism is both faster than the serial recurrence used in RNNs, and also makes the Universal Transformer more powerful than the standard feedforward Transformer. ...
2018b
- (Liu et al., 2018) ⇒ Peter J. Liu, Mohammad Saleh, Etienne Pot, Ben Goodrich, Ryan Sepassi, Lukasz Kaiser, and Noam Shazeer. (2018). “Generating Wikipedia by Summarizing Long Sequences.” In: Proceedings of the Sixth International Conference on Learning Representations (ICLR-2018).
- QUOTE: ... We describe the first attempt to abstractively generate the first section, or lead, of Wikipedia articles conditioned on reference text. In addition to running strong baseline models on the task, we modify the Transformer architecture (Vaswani et al., 2017) to only consist of a decoder, which performs better in the case of longer input sequences compared to recurrent neural network (RNN) and Transformer encoder-decoder models. ...
2018c
- (Wolf, 2018) ⇒ Alex Wolf. (2018). "Attention and Translation Systems." (Video). Presentation at Deep Learning NYC.
2018d
- (Ng, 2018) ⇒ Andrew Ng. (2018). "C5W3L08 Attention Model." (Video)
2018e
- (Alammar,2018) ⇒ Jay Alammar. (2018). “The Illustrated Transformer."
- QUOTE: ... In this post, we will look at The Transformer – a model that uses attention to boost the speed with which these models can be trained. ... The biggest benefit, however, comes from how The Transformer lends itself to parallelization. ...
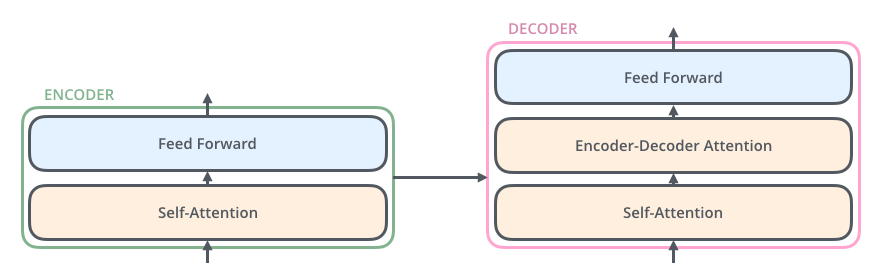
The encoder’s inputs first flow through a self-attention layer – a layer that helps the encoder look at other words in the input sentence as it encodes a specific word. We’ll look closer at self-attention later in the post. The outputs of the self-attention layer are fed to a feed-forward neural network. The exact same feed-forward network is independently applied to each position. The decoder has both those layers, but between them is an attention layer that helps the decoder focus on relevant parts of the input sentence (similar what attention does in seq2seq models).
- QUOTE: ... In this post, we will look at The Transformer – a model that uses attention to boost the speed with which these models can be trained. ... The biggest benefit, however, comes from how The Transformer lends itself to parallelization. ...
2017b
- (Uszkoreit, 2019) ⇒ Jakob Uszkoreit (August, 2017). "Transformer: A Novel Neural Network Architecture for Language Understanding". In: Google AI Blog.
- QUOTE: ... In contrast, the Transformer only performs a small, constant number of steps (chosen empirically). In each step, it applies a self-attention mechanism which directly models relationships between all words in a sentence, regardless of their respective position. In the earlier example “I arrived at the bank after crossing the river”, to determine that the word “bank” refers to the shore of a river and not a financial institution, the Transformer can learn to immediately attend to the word “river” and make this decision in a single step. In fact, in our English-French translation model we observe exactly this behavior. More specifically, to compute the next representation for a given word - “bank” for example - the Transformer compares it to every other word in the sentence. The result of these comparisons is an attention score for every other word in the sentence. These attention scores determine how much each of the other words should contribute to the next representation of “bank”. In the example, the disambiguating “river” could receive a high attention score when computing a new representation for “bank”. The attention scores are then used as weights for a weighted average of all words’ representations which is fed into a fully-connected network to generate a new representation for “bank”, reflecting that the sentence is talking about a river bank. The animation below illustrates how we apply the Transformer to machine translation. Neural networks for machine translation typically contain an encoder reading the input sentence and generating a representation of it. A decoder then generates the output sentence word by word while consulting the representation generated by the encoder. The Transformer starts by generating initial representations, or embeddings, for each word. These are represented by the unfilled circles. Then, using self-attention, it aggregates information from all of the other words, generating a new representation per word informed by the entire context, represented by the filled balls. This step is then repeated multiple times in parallel for all words, successively generating new representations.

The decoder operates similarly, but generates one word at a time, from left to right. It attends not only to the other previously generated words, but also to the final representations generated by the encoder.
- QUOTE: ... In contrast, the Transformer only performs a small, constant number of steps (chosen empirically). In each step, it applies a self-attention mechanism which directly models relationships between all words in a sentence, regardless of their respective position. In the earlier example “I arrived at the bank after crossing the river”, to determine that the word “bank” refers to the shore of a river and not a financial institution, the Transformer can learn to immediately attend to the word “river” and make this decision in a single step. In fact, in our English-French translation model we observe exactly this behavior. More specifically, to compute the next representation for a given word - “bank” for example - the Transformer compares it to every other word in the sentence. The result of these comparisons is an attention score for every other word in the sentence. These attention scores determine how much each of the other words should contribute to the next representation of “bank”. In the example, the disambiguating “river” could receive a high attention score when computing a new representation for “bank”. The attention scores are then used as weights for a weighted average of all words’ representations which is fed into a fully-connected network to generate a new representation for “bank”, reflecting that the sentence is talking about a river bank. The animation below illustrates how we apply the Transformer to machine translation. Neural networks for machine translation typically contain an encoder reading the input sentence and generating a representation of it. A decoder then generates the output sentence word by word while consulting the representation generated by the encoder. The Transformer starts by generating initial representations, or embeddings, for each word. These are represented by the unfilled circles. Then, using self-attention, it aggregates information from all of the other words, generating a new representation per word informed by the entire context, represented by the filled balls. This step is then repeated multiple times in parallel for all words, successively generating new representations.
2017a
- (Vaswani et al., 2017) ⇒ Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. (2017). “Attention is all You Need.” In: Advances in Neural Information Processing Systems (NIPS-2017).
- QUOTE: The Transformer follows this overall architecture using stacked self-attention and pointwise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure 1, respectively.
 Figure 1: The Transformer-model architecture.
Figure 1: The Transformer-model architecture.
- QUOTE: The Transformer follows this overall architecture using stacked self-attention and pointwise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure 1, respectively.
