Stacked Prediction Model
A Stacked Prediction Model is an ensemble model that is produced by a stacked learning system (which learns the model combination function).
- Context:
- It can be produced by a Stacked Model Learning System (that can solve a stacked model learning task).
- Example(s):
- the winning Netflix Prize model.
- …
- Counter-Example(s):
- a Random Forests Model.
- a Boosted Prediction Model, such as a Gradient Boosted Tree model.
- See: Stacked Auto-Encoder, Ensemble Learning, Stacking.
References
2015
- (Wikipedia, 2015) ⇒ http://en.wikipedia.org/wiki/ensemble_learning#Stacking Retrieved:2015-5-3.
- Stacking (sometimes called stacked generalization) involves training a learning algorithm to combine the predictions of several other learning algorithms. First, all of the other algorithms are trained using the available data, then a combiner algorithm is trained to make a final prediction using all the predictions of the other algorithms as additional inputs. If an arbitrary combiner algorithm is used, then stacking can theoretically represent any of the ensemble techniques described in this article, although in practice, a single-layer logistic regression model is often used as the combiner.
Stacking typically yields performance better than any single one of the trained models. [1] It has been successfully used on both supervised learning tasks (regression, [2] classification and distance learning [3] ) and unsupervised learning (density estimation). [4] It has also been used to estimate bagging's error rate. [5] It has been reported to out-perform Bayesian model-averaging. [6] The two top-performers in the Netflix competition utilized blending, which may be considered to be a form of stacking. [7]
- Stacking (sometimes called stacked generalization) involves training a learning algorithm to combine the predictions of several other learning algorithms. First, all of the other algorithms are trained using the available data, then a combiner algorithm is trained to make a final prediction using all the predictions of the other algorithms as additional inputs. If an arbitrary combiner algorithm is used, then stacking can theoretically represent any of the ensemble techniques described in this article, although in practice, a single-layer logistic regression model is often used as the combiner.
- ↑ Wolpert, D., Stacked Generalization., Neural Networks, 5(2), pp. 241-259., 1992
- ↑ Breiman, L., Stacked Regression, Machine Learning, 24, 1996
- ↑ M. Ozay and F. T. Yarman Vural, A New Fuzzy Stacked Generalization Technique and Analysis of its Performance, 2012, arXiv:1204.0171
- ↑ Smyth, P. and Wolpert, D. H., Linearly Combining Density Estimators via Stacking, Machine Learning Journal, 36, 59-83, 1999
- ↑ Wolpert, D.H., and Macready, W.G., An Efficient Method to Estimate Bagging’s Generalization Error, Machine Learning Journal, 35, 41-55, 1999
- ↑ Clarke, B., Bayes model averaging and stacking when model approximation error cannot be ignored, Journal of Machine Learning Research, pp 683-712, 2003
- ↑ Sill, J. and Takacs, G. and Mackey L. and Lin D., Feature-Weighted Linear Stacking, 2009, arXiv:0911.0460
2013
- http://www.chioka.in/stacking-blending-and-stacked-generalization/
- QUOTE: Stacking, Blending and and Stacked Generalization are all the same thing with different names. It is a kind of ensemble learning.
In traditional ensemble learning, we have multiple classifiers trying to fit to a training set to approximate the target function. Since each classifier will have its own output, we will need to find a combining mechanism to combine the results. This can be through voting (majority wins), weighted voting (some classifier has more authority than the others), averaging the results, etc. This is the traditional way of ensemble learning. In stacking, the combining mechanism is that the output of the classifiers (Level 0 classifiers) will be used as training data for another classifier (Level 1 classifier) to approximate the same target function. Basically, you let the Level 1 classifier to figure out the combining mechanism.
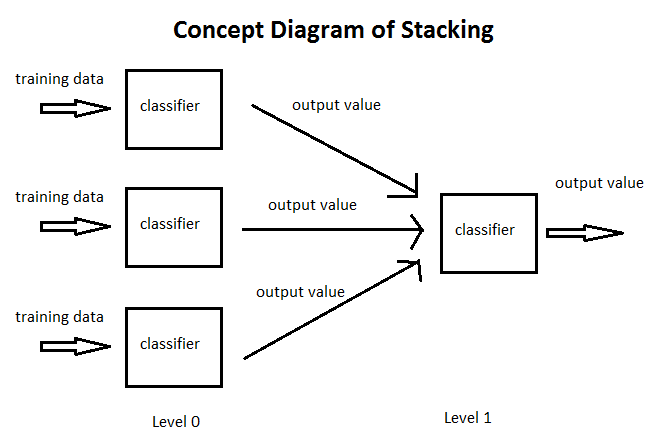
In practice, this works very well. In fact, it is most famously used in Netflix to achieve a very good score.
- QUOTE: Stacking, Blending and and Stacked Generalization are all the same thing with different names. It is a kind of ensemble learning.
1992
- (Wolpert, 1992) ⇒ David H. Wolpert. (1992). “Stacked generalization." Neural Networks, 5(2).