SegNet Convolutional Encoder-Decoder Neural Network
A SegNet Convolutional Encoder-Decoder Neural Network is a CNN encoder-decoder network that can perform the semantic segmentation of an image.
- Example(s):
- …
- Counter-Example(s):
- See: Sequence-to-Sequence Learning Task, Artificial Neural Network, Bidirectional Neural Network, Convolutional Neural Network, Neural Machine Translation Task, Deep Learning, Natural Language Processing.
References
2018
- (Saxena, 2018) ⇒ Rohan Saxena (April, 2018). "What is an Encoder/Decoder in Deep Learning?".
- QUOTE: In a CNN, an encoder-decoder network typically looks like this (a CNN encoder and a CNN decoder):
Image Credits: (Badrinarayanan et al., 2017)
This is a network to perform semantic segmentation of an image. The left half of the network maps raw image pixels to a rich representation of a collection of feature vectors. The right half of the network takes these features, produces an output and maps the output back into the “raw” format (in this case, image pixels). ...
- QUOTE: In a CNN, an encoder-decoder network typically looks like this (a CNN encoder and a CNN decoder):
2017
- (Badrinarayanan et al., 2017) ⇒ Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla. (2017). “SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation.” In: IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(12). doi:10.1109/TPAMI.2016.2644615
- QUOTE: SegNet has an encoder network and a corresponding decoder network, followed by a final pixelwise classification layer. This architecture is illustrated in Fig. 2. The encoder network consists of 13 convolutional layers which correspond to the first 13 convolutional layers in the VGG16 network (Simonyan & Zisserman, 2014) designed for object classification. ...
Each encoder layer has a corresponding decoder layer and hence the decoder network has 13 layers. The final decoder output is fed to a multi-class soft-max classifier to produce class probabilities for each pixel independently.
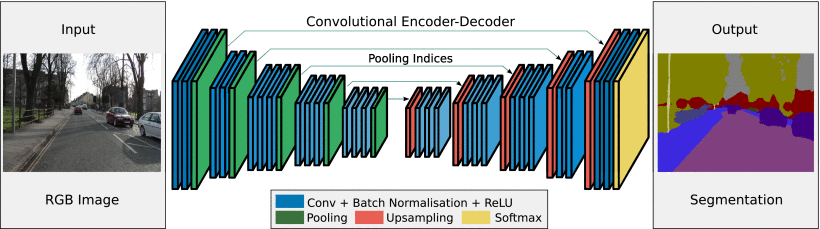
Figure 2. An illustration of the SegNet architecture. There are no fully connected layers and hence it is only convolutional. A decoder upsamples its input using the transferred pool indices from its encoder to produce a sparse feature map(s). It then performs convolution with a trainable filter bank to densify the feature map. The final decoder output feature maps are fed to a soft-max classifier for pixel-wise classification.
- QUOTE: SegNet has an encoder network and a corresponding decoder network, followed by a final pixelwise classification layer. This architecture is illustrated in Fig. 2. The encoder network consists of 13 convolutional layers which correspond to the first 13 convolutional layers in the VGG16 network (Simonyan & Zisserman, 2014) designed for object classification.