Logistic Sigmoid Activation Function
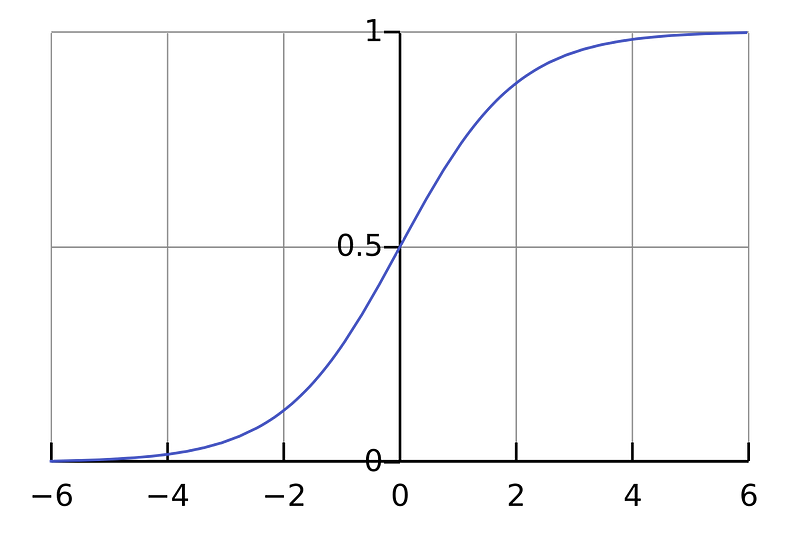
A Logistic Sigmoid Activation Function is a neuron activation function based on a logistic sigmoid function, [math]\displaystyle{ f(x)=(1+e^{−x})^{-1} }[/math].
- AKA: Soft Step Activation Function.
- Context:
- It can (typically) be used in the activation of Sigmoid Neurons.
- Example(s):
torch.nn.Sigmoid- PyTorch implementation,- …
- Counter-Example(s):
- See: Artificial Neural Network, Artificial Neuron, Neural Network Topology, Neural Network Layer, Neural Network Learning Rate.
References
2018a
- (Santos, 2018) ⇒ Santos (2018) "Activation Functions". In: Neural Networks - Artificial Inteligence Retrieved: 2018-01-28.
- QUOTE: After the neuron do the dot product between it's inputs and weights, it also apply a non-linearity on this result. This non-linear function is called Activation Function.
On the past the popular choice for activation functions were the sigmoid and tanh. Recently it was observed the ReLU layers has better response for deep neural networks, due to a problem called vanishing gradient. So you can consider using only ReLU neurons.
sigmoid: [math]\displaystyle{ \sigma(x)=\dfrac{1}{1+e^{−x}} }[/math]
tanh:[math]\displaystyle{ \sigma(x)=\dfrac{e^x−e^x}{e^x+e^x} }[/math]
ReLU:[math]\displaystyle{ \sigma(x)=max(0,x) }[/math]

- QUOTE: After the neuron do the dot product between it's inputs and weights, it also apply a non-linearity on this result. This non-linear function is called Activation Function.
2018b
- (CS231n, 2018) ⇒ Commonly used activation functions. In: CS231n Convolutional Neural Networks for Visual Recognition Retrieved: 2018-01-28.
- QUOTE: Every activation function (or non-linearity) takes a single number and performs a certain fixed mathematical operation on it. There are several activation functions you may encounter in practice:
- Sigmoid. The sigmoid non-linearity has the mathematical form [math]\displaystyle{ \sigma(x)=1/(1+e^{−x}) }[/math] and is shown in the image above on the left. As alluded to in the previous section, it takes a real-valued number and “squashes” it into range between 0 and 1. In particular, large negative numbers become 0 and large positive numbers become 1. The sigmoid function has seen frequent use historically since it has a nice interpretation as the firing rate of a neuron: from not firing at all (0) to fully-saturated firing at an assumed maximum frequency (1). In practice, the sigmoid non-linearity has recently fallen out of favor and it is rarely ever used. It has two major drawbacks:
- Sigmoids saturate and kill gradients. A very undesirable property of the sigmoid neuron is that when the neuron’s activation saturates at either tail of 0 or 1, the gradient at these regions is almost zero. Recall that during backpropagation, this (local) gradient will be multiplied to the gradient of this gate’s output for the whole objective. Therefore, if the local gradient is very small, it will effectively “kill” the gradient and almost no signal will flow through the neuron to its weights and recursively to its data. Additionally, one must pay extra caution when initializing the weights of sigmoid neurons to prevent saturation. For example, if the initial weights are too large then most neurons would become saturated and the network will barely learn.
- Sigmoid outputs are not zero-centered. This is undesirable since neurons in later layers of processing in a Neural Network (more on this soon) would be receiving data that is not zero-centered. This has implications on the dynamics during gradient descent, because if the data coming into a neuron is always positive (e.g. [math]\displaystyle{ x gt 0 }[/math] elementwise in [math]\displaystyle{ f=wTx+b }[/math]), then the gradient on the weights [math]\displaystyle{ w }[/math] will during backpropagation become either all be positive, or all negative (depending on the gradient of the whole expression [math]\displaystyle{ f }[/math]). This could introduce undesirable zig-zagging dynamics in the gradient updates for the weights. However, notice that once these gradients are added up across a batch of data the final update for the weights can have variable signs, somewhat mitigating this issue. Therefore, this is an inconvenience but it has less severe consequences compared to the saturated activation problem above.
- QUOTE: Every activation function (or non-linearity) takes a single number and performs a certain fixed mathematical operation on it. There are several activation functions you may encounter in practice:
2017
- (Mate Labs, 2017) ⇒ Mate Labs Aug 23, 2017. Secret Sauce behind the beauty of Deep Learning: Beginners guide to Activation Functions
- QUOTE: Sigmoid or Logistic activation function(Soft Step)-It is mostly used for binary classification problems (i.e. outputs values that range 0–1) . It has problem of vanishing gradients. The network refuses to learn or the learning is very slow after certain epochs because input(X) is causing very small change in output(Y). It is a widely used activation function for classification problems, but recently. This function is more prone to saturation of the later layers, making training more difficult. Calculating derivative of Sigmoid function is very easy.
For the backpropagation process in a neural network, your errors will be squeezed by (at least) a quarter at each layer. Therefore, deeper your network is, more knowledge from the data will be “lost”. Some “big” errors we get from the output layer might not be able to affect the synapses weight of a neuron in a relatively shallow layer much (“shallow” means it’s close to the input layer) — Source https://github.com/Kulbear/deep-learning-nano-foundation/wiki/ReLU-and-Softmax-Activation-Functions
Sigmoid or Logistic activation function:
[math]\displaystyle{ f(x)=\dfrac{1}{1 + e^{-x}} }[/math]
[math]\displaystyle{ f'(x)=f(x)(1-f(x)) }[/math]
Range: (0, 1)
Examples: f(4) = 0.982, f(-3) = 0.0474, f(-5) = 0.0067
- QUOTE: Sigmoid or Logistic activation function(Soft Step)-It is mostly used for binary classification problems (i.e. outputs values that range 0–1) . It has problem of vanishing gradients. The network refuses to learn or the learning is very slow after certain epochs because input(X) is causing very small change in output(Y). It is a widely used activation function for classification problems, but recently. This function is more prone to saturation of the later layers, making training more difficult. Calculating derivative of Sigmoid function is very easy.
2016
- (Garcia et al., 2016) ⇒ García Benítez, S. R., López Molina, J. A., & Castellanos Pedroza, V. (2016). Neural networks for defining spatial variation of rock properties in sparsely instrumented media. Boletín de la Sociedad Geológica Mexicana, 68(3), 553-570.
- QUOTE: The activation function of the neurons in NN implementing the backpropagation algorithm is a weighted sum (the sum of the inputs [math]\displaystyle{ x_i }[/math] multiplied by their respective weights [math]\displaystyle{ w_{ji} }[/math]:
[math]\displaystyle{ A_j(\hat{x},\hat{w})=\sum_{i=0}^n x_iw_{ji} }[/math]
As can be seen, the neuron activation depends only on the inputs and the weights. If the output function would be the identity (activation = output) then the neuron would be called linear. But these have severe limitations, the most common output function is the sigmoidal function:
[math]\displaystyle{ O_j=\dfrac{1}{1+e^{-A_j(\hat{x},\hat{w})}} }[/math]
The sigmoidal function is very close to one for large positive numbers, 0.5 at zero, and very close to zero for large negative numbers. This allows a smooth transition between the low and high out-puts (close to zero or close to one). The goal of the training process is to obtain a desired output when certain inputs are given. Since the error is the difference between the actual and the desired output, the error depends on the weights, and we need to adjust the weights in order to minimize the error.
- QUOTE: The activation function of the neurons in NN implementing the backpropagation algorithm is a weighted sum (the sum of the inputs [math]\displaystyle{ x_i }[/math] multiplied by their respective weights [math]\displaystyle{ w_{ji} }[/math]:
2005
- (Golda,2005) ⇒ Adam Golda (2005). "Introduction to neural networks"
- QUOTE: Functions that more accurate describe the non-linear characteristic of the biological neuron activation function are:
sigmoid function:
[math]\displaystyle{ y=\dfrac{1}{1+\exp({-\beta\varphi})} }[/math]
where [math]\displaystyle{ \beta }[/math] is a parameter,
and hyperbolic tangent function:[math]\displaystyle{ y=tgh\left(\dfrac{\alpha\varphi}{2}\right)=\dfrac{1 - \exp({-\alpha\varphi})}{1+\exp({-\alpha\varphi})} }[/math] where [math]\displaystyle{ \alpha }[/math] is a parameter.
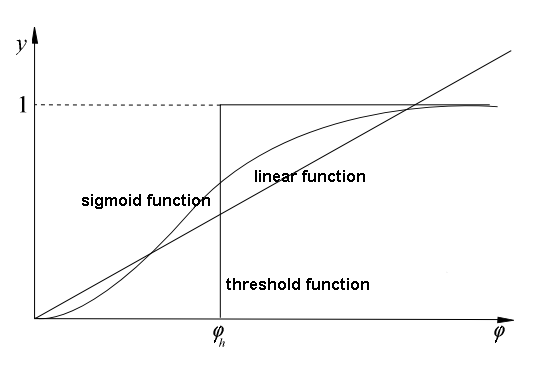
The next picture presents the graphs of particular activation functions:
- QUOTE: Functions that more accurate describe the non-linear characteristic of the biological neuron activation function are:
- a. linear function,
- b. threshold function,
- c. sigmoid function.