Multilayer Feedforward Neural Network Training System
A Multilayer Feedforward Neural Network Training System is a feed-forward neural network training system that applies a multi-layer feed-forward neural network training algorithm to solve a multi-layer feed-forward neural network training task.
- Context:
- It is a supervised learning system that is based on the backpropagation system.
- It produces a Multilayer Feedforward Neural Network.
- Example(s)
- Counter-Example(s)
- See: Online Learning, Document Classification, Backpropagation, Learning Curve, POS Tagging, Feature Selection, Active Learning Theory, Text Mining, Adaptive Resonance Theory, Neural Network, Natural Language Processing, Feedforward Neural Network, Artificial Neural Network, Activation Function, Supervised Learning, Linear Separability.
References
2017a
- (sklearn, 2017) ⇒ http://scikit-learn.org/stable/modules/neural_networks_supervised.html#multi-layer-perceptron Retrieved:2017-12-3.
- QUOTE: Multi-layer Perceptron (MLP) is a supervised learning algorithm that learns a function [math]\displaystyle{ f(\cdot): R^m \rightarrow R^o }[/math] by training on a dataset, where [math]\displaystyle{ m }[/math] is the number of dimensions for input and [math]\displaystyle{ o }[/math] is the number of dimensions for output. Given a set of features [math]\displaystyle{ X = {x_1, x_2, \cdots, x_m} }[/math] and a target [math]\displaystyle{ y }[/math], it can learn a non-linear function approximator for either classification or regression. It is different from logistic regression, in that between the input and the output layer, there can be one or more non-linear layers, called hidden layers. Figure 1 shows a one hidden layer MLP with scalar output.
The leftmost layer, known as the input layer, consists of a set of neurons [math]\displaystyle{ \{x_i | x_1, x_2, \cdots, x_m\} }[/math] representing the input features. Each neuron in the hidden layer transforms the values from the previous layer with a weighted linear summation [math]\displaystyle{ w_1x_1 + w_2x_2 + \cdots + w_mx_m }[/math], followed by a non-linear activation function [math]\displaystyle{ g(\cdot):R \rightarrow R - }[/math] like the hyperbolic tan function. The output layer receives the values from the last hidden layer and transforms them into output values.
The module contains the public attributes
coefs_andintercepts_.coefs_is a list of weight matrices, where weight matrix at index [math]\displaystyle{ i }[/math] represents the weights between layer [math]\displaystyle{ i }[/math] and layer [math]\displaystyle{ i+1 }[/math].intercepts_is a list of bias vectors, where the vector at index [math]\displaystyle{ i }[/math] represents the bias values added to layer [math]\displaystyle{ i+1 }[/math].The advantages of Multi-layer Perceptron are:
- Capability to learn non-linear models.
- Capability to learn models in real-time (on-line learning) using
partial_fit.
- QUOTE: Multi-layer Perceptron (MLP) is a supervised learning algorithm that learns a function [math]\displaystyle{ f(\cdot): R^m \rightarrow R^o }[/math] by training on a dataset, where [math]\displaystyle{ m }[/math] is the number of dimensions for input and [math]\displaystyle{ o }[/math] is the number of dimensions for output. Given a set of features [math]\displaystyle{ X = {x_1, x_2, \cdots, x_m} }[/math] and a target [math]\displaystyle{ y }[/math], it can learn a non-linear function approximator for either classification or regression. It is different from logistic regression, in that between the input and the output layer, there can be one or more non-linear layers, called hidden layers. Figure 1 shows a one hidden layer MLP with scalar output.
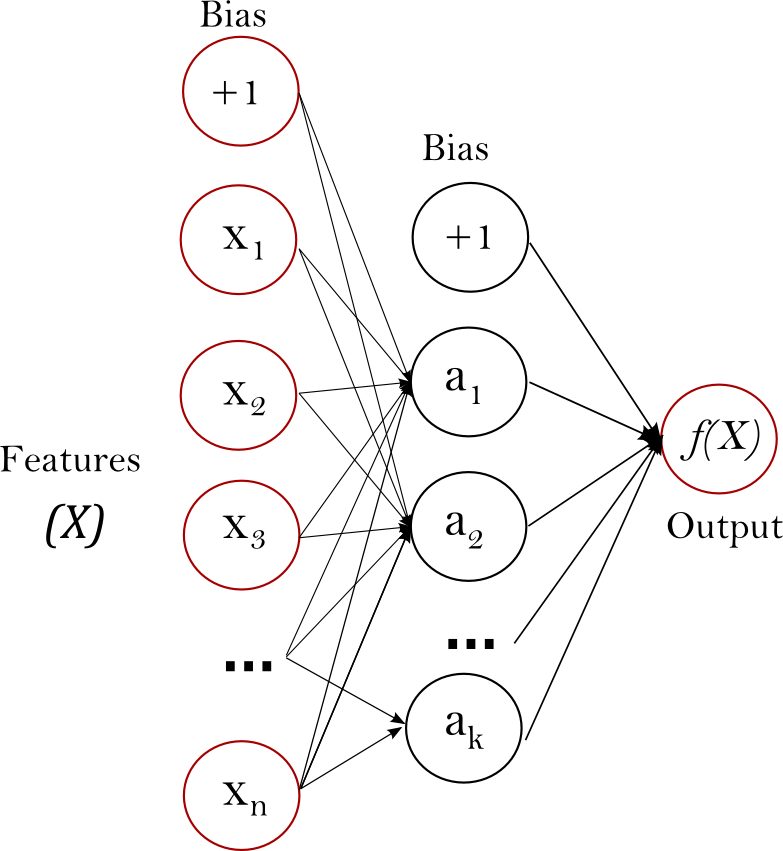{kind=link}
- The disadvantages of Multi-layer Perceptron (MLP) include:
- MLP with hidden layers have a non-convex loss function where there exists more than one local minimum. Therefore different random weight initializations can lead to different validation accuracy.
- MLP requires tuning a number of hyperparameters such as the number of hidden neurons, layers, and iterations.
- MLP is sensitive to feature scaling.
- The disadvantages of Multi-layer Perceptron (MLP) include:
2017b
- (Wikipedia, 2017) ⇒ https://en.wikipedia.org/wiki/Multilayer_perceptron Retrieved:2017-12-3.
- A multilayer perceptron (MLP) is a class of feedforward artificial neural network. An MLP consists of at least three layers of nodes. Except for the input nodes, each node is a neuron that uses a nonlinear activation function. MLP utilizes a supervised learning technique called backpropagation for training. [1] [2] Its multiple layers and non-linear activation distinguish MLP from a linear perceptron. It can distinguish data that is not linearly separable.[3] Multilayer perceptrons are sometimes colloquially referred to as "vanilla" neural networks, especially when they have a single hidden layer. [4]
- ↑ Rosenblatt, Frank. x. Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms. Spartan Books, Washington DC, 1961
- ↑ Rumelhart, David E., Geoffrey E. Hinton, and R. J. Williams. “Learning Internal Representations by Error Propagation". David E. Rumelhart, James L. McClelland, and the PDP research group. (editors), Parallel distributed processing: Explorations in the microstructure of cognition, Volume 1: Foundation. MIT Press, 1986.
- ↑ Cybenko, G. 1989. Approximation by superpositions of a sigmoidal function Mathematics of Control, Signals, and Systems, 2(4), 303–314.
- ↑ Hastie, Trevor. Tibshirani, Robert. Friedman, Jerome. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer, New York, NY, 2009.