MOSES Statistical Machine Translation System
A MOSES Statistical Machine Translation System is a statistical MT system that implements a MOSES Statistical Machine Translation Algorithm to solve a MOSES Statistical Machine Translation Task.
- Context:
- …
- Example(s):
- Counter-Example(s):
- See: Factored Translation Model, Confusion Network, Word Lattice, EuroMatrix, TC-STAR, EuroMatrixPlus, LetsMT, META-NET, MosesCore, MateCat.
References
2020
- (Moses, 2020) ⇒ http://www.statmt.org/moses/ Retrieved:2020-09-27.
- QUOTE: Moses is a statistical machine translation system that allows you to automatically train translation models for any language pair. All you need is a collection of translated texts (parallel corpus). Once you have a trained model, an efficient search algorithm quickly finds the highest probability translation among the exponential number of choices.
- Features:
- Moses offers two types of translation models: phrase-based and tree-based.
- Moses features factored translation models, which enable the integration linguistic and other information at the word level.
- Moses allows the decoding of confusion networks and word lattices, enabling easy integration with ambiguous upstream tools, such as automatic speech recognizers or morphological analyzers.
- The Experiment Management System makes using Moses much easier
2020
- http://www.statmt.org/moses/?n=Moses.Background
- QUOTE: The figure below illustrates the process of phrase-based translation. The input is segmented into a number of sequences of consecutive words (so-called phrases). Each phrase is translated into an English phrase, and English phrases in the output may be reordered.
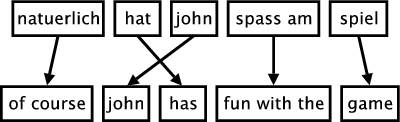 ...
...
- QUOTE: The figure below illustrates the process of phrase-based translation. The input is segmented into a number of sequences of consecutive words (so-called phrases). Each phrase is translated into an English phrase, and English phrases in the output may be reordered.
2018
- (Lee et al., 2018) ⇒ Chris van der Lee, Emiel Krahmer, and Sander Wubben. (2018). “Automated Learning of Templates for Data-to-text Generation: Comparing Rule-based, Statistical and Neural Methods". In: Proceedings of the 11th International Conference on Natural Language Generation (INLG 2018). DOI:10.18653/v1/W18-6504.
- QUOTE: ... The MOSES toolkit (Koehn et al., 2007) was used for SMT. This Statistical Machine Translation system uses Bayes’s rule to translate a source language string into a target language string. For this, it needs a translation model and a language model. The translation model was obtained from the parallel corpora described above, while the language model used in the current work is obtained from the text part of the aligned corpora. Translation in the MOSES toolkit is based on a set of heuristics.
2015
- (Rush et al., 2015) ⇒ Alexander M. Rush, Sumit Chopra, and Jason Weston. (2015). “A Neural Attention Model for Abstractive Sentence Summarization.” In: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP-2015). DOI:10.18653/v1/D15-1044.
- QUOTE: To control for memorizing titles from training, we implement an information retrieval baseline, IR. This baseline indexes the training set, and gives the title for the article with highest BM-25 match to the input (see Manning et al. (2008)). Finally, we use a phrase-based statistical machine translation system trained on Gigaword to produce summaries, MOSES + (Koehn et al., 2007).
2007
- (Koehn et al., 2007) ⇒ Philipp Koehn, Hieu Hoang, Alexandra Birch, Chris Callison-Burch, Marcello Federico, Nicola Bertoldi, Brooke Cowan, Wade Shen, Christine Moran, Richard Zens, Chris Dyer, Ondrej Bojar, Alexandra Constantin, and Evan Herbst. (2007). “Moses: Open Source Toolkit for Statistical Machine Translation". In: Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics Companion Volume Proceedings of the Demo and Poster Sessions (ACL 2007).
- QUOTE: Apart from providing an open-source toolkit for SMT, a further motivation for Moses is to extend phrase-based translation with factors and confusion network decoding.
The current phrase-based approach to statistical machine translation is limited to the mapping of small text chunks without any explicit use of linguistic information, be it morphological, syntactic, or semantic. These additional sources of information have been shown to be valuable when integrated into pre-processing or post-processing steps.
Moses also integrates confusion network decoding, which allows the translation of ambiguous input. This enables, for instance, the tighter integration of speech recognition and machine translation. Instead of passing along the one-best output of the recognizer, a network of different word choices may be examined by the machine translation system.
Efficient data structures in Moses for the memory-intensive translation model and language model allow the exploitation of much larger data resources with limited hardware.
- QUOTE: Apart from providing an open-source toolkit for SMT, a further motivation for Moses is to extend phrase-based translation with factors and confusion network decoding.