Machine Learning (ML) Training Step
A Machine Learning (ML) Training Step is an Machine Learning Algorithm's Iteration Step that is a complete update cycle of weights and biases parameters.
- Example(s):
- …
- Counter-Example(s):
- See: Machine Learning System, Supervised Machine Learning Algorithm, Unsupervised Machine Learning Algorithm, Training Dataset, Test Dataset, Validation Dataset, Computational Learning Theory.
References
2019
- (Wikipedia, 2019) ⇒ https://en.wikipedia.org/wiki/Machine_learning#Machine_learning_tasks Retrieved:2019-12-29.
- Machine learning tasks are classified into several broad categories. In supervised learning, the algorithm builds a mathematical model from a set of data that contains both the inputs and the desired outputs. For example, if the task were determining whether an image contained a certain object, the training data for a supervised learning algorithm would include images with and without that object (the input), and each image would have a label (the output) designating whether it contained the object. In special cases, the input may be only partially available, or restricted to special feedback.Semi-supervised learning algorithms develop mathematical models from incomplete training data, where a portion of the sample input doesn't have labels.
Classification algorithms and regression algorithms are types of supervised learning. Classification algorithms are used when the outputs are restricted to a limited set of values. For a classification algorithm that filters emails, the input would be an incoming email, and the output would be the name of the folder in which to file the email. For an algorithm that identifies spam emails, the output would be the prediction of either “spam” or "not spam", represented by the Boolean values true and false. Regression algorithms are named for their continuous outputs, meaning they may have any value within a range. Examples of a continuous value are the temperature, length, or price of an object.
In unsupervised learning, the algorithm builds a mathematical model from a set of data that contains only inputs and no desired output labels. Unsupervised learning algorithms are used to find structure in the data, like grouping or clustering of data points. Unsupervised learning can discover patterns in the data, and can group the inputs into categories, as in feature learning. Dimensionality reduction is the process of reducing the number of “features", or inputs, in a set of data.
Active learning algorithms access the desired outputs (training labels) for a limited set of inputs based on a budget and optimize the choice of inputs for which it will acquire training labels. When used interactively, these can be presented to a human user for labeling. Reinforcement learning algorithms are given feedback in the form of positive or negative reinforcement in a dynamic environment and are used in autonomous vehicles or in learning to play a game against a human opponent.[1]Other specialized algorithms in machine learning include topic modeling, where the computer program is given a set of natural language documents and finds other documents that cover similar topics. Machine learning algorithms can be used to find the unobservable probability density function in density estimation problems. Meta learning algorithms learn their own inductive bias based on previous experience. In developmental robotics, robot learning algorithms generate their own sequences of learning experiences, also known as a curriculum, to cumulatively acquire new skills through self-guided exploration and social interaction with humans. These robots use guidance mechanisms such as active learning, maturation, motor synergies, and imitation.
- Machine learning tasks are classified into several broad categories. In supervised learning, the algorithm builds a mathematical model from a set of data that contains both the inputs and the desired outputs. For example, if the task were determining whether an image contained a certain object, the training data for a supervised learning algorithm would include images with and without that object (the input), and each image would have a label (the output) designating whether it contained the object. In special cases, the input may be only partially available, or restricted to special feedback.Semi-supervised learning algorithms develop mathematical models from incomplete training data, where a portion of the sample input doesn't have labels.
- ↑ Bishop, C. M. (2006), Pattern Recognition and Machine Learning, Springer, ISBN 978-0-387-31073-2
2017
- (Yufeng G, 2017) ⇒ Yufeng G (Aug 31, 2017) "The 7 Steps of Machine Learning". In: Medium - Towards Data Science Blog.
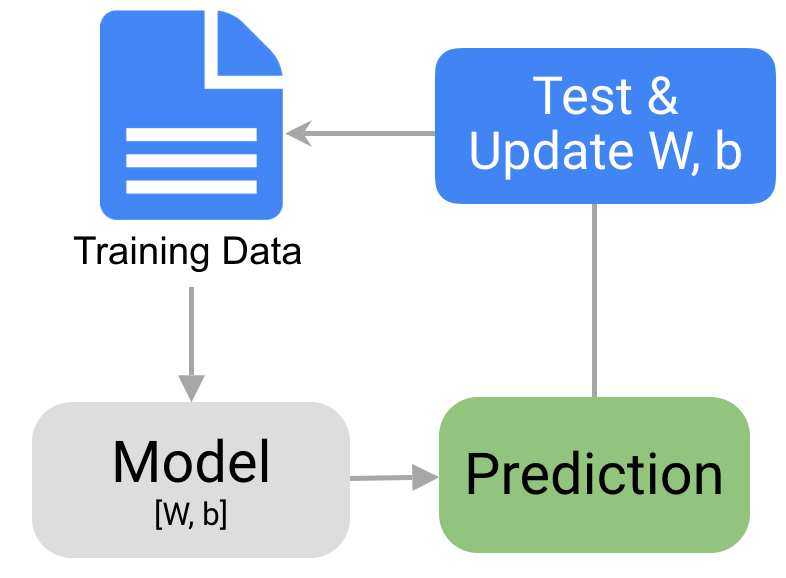
- QUOTE: In particular, the formula for a straight line is $y=m*x+b$, where $x$ is the input, $m$ is the slope of that line, $b$ is the $y$-intercept, and $y$ is the value of the line at the position $x$. The values we have available to us for adjusting, or “training”, are $m$ and $b$. There is no other way to affect the position of the line, since the only other variables are $x$, our input, and $y$, our output.
In machine learning, there are many $m$’s since there may be many features. The collection of these $m$ values is usually formed into a matrix, that we will denote $W$, for the “weights” matrix. Similarly for $b$, we arrange them together and call that the biases.
The training process involves initializing some random values for $W$ and $b$ and attempting to predict the output with those values. As you might imagine, it does pretty poorly. But we can compare our model’s predictions with the output that it should produced, and adjust the values in $W$ and $b$ such that we will have more correct predictions.
This process then repeats. Each iteration or cycle of updating the weights and biases is called one training “step”.
- QUOTE: In particular, the formula for a straight line is $y=m*x+b$, where $x$ is the input, $m$ is the slope of that line, $b$ is the $y$-intercept, and $y$ is the value of the line at the position $x$. The values we have available to us for adjusting, or “training”, are $m$ and $b$. There is no other way to affect the position of the line, since the only other variables are $x$, our input, and $y$, our output.