LLM In-Context Needle-in-a-Haystack Recall Measure
Jump to navigation
Jump to search
A LLM In-Context Needle-in-a-Haystack Recall Measure is a LLM in-context recall measure for an LLM needle-in-a-haystack IR task based on its ability recall specific, often obscure, information ("needle") from within a large body of text ("haystack").
- Context:
- It can (typically) employ Benchmarking Tests to assess the precision of LLMs in identifying and retrieving minute details accurately amidst extensive textual data.
- It can be a stringent test of a model's Contextual Understanding and Memory Capability (critical in applications like Legal Document Review or Scientific Research where missing crucial details can have significant consequences).
- It can (often) use metrics similar to those used in traditional Information Retrieval tasks but focuses specifically on the recall aspect, ensuring the model not only identifies but also correctly retrieves the information without being overwhelmed by the volume of the context.
- It can show variability in performance based on the position of the information within the document, with better recall typically noted when the information is placed at the beginning or very end of the text.
- ...
- Example(s):
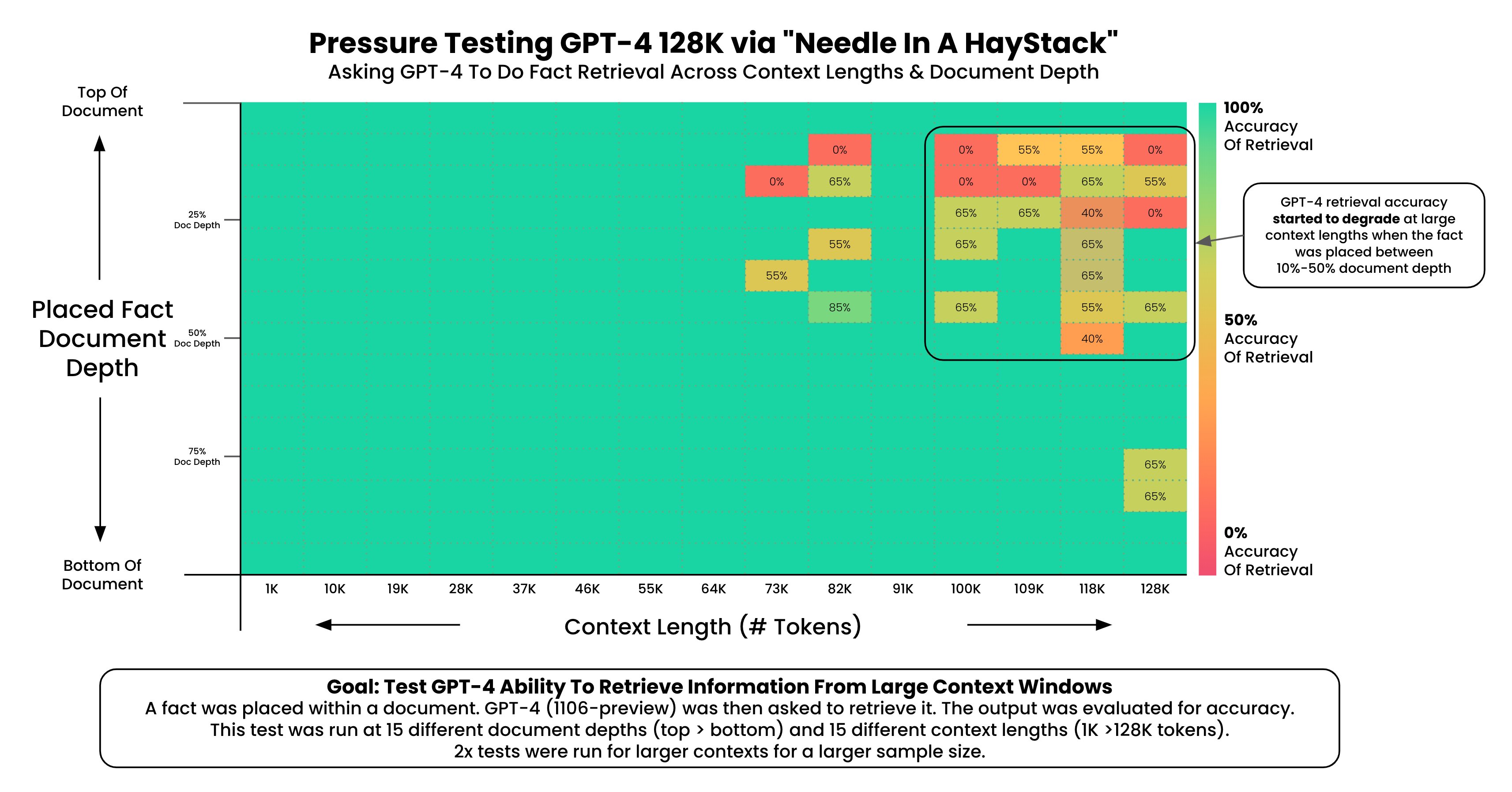
- One based on a test where the 'needle' is deliberately hidden within a 'haystack' of 128,000 tokens to analyze the recall capabilities of GPT-4 under varied contextual lengths and positions.
- One based on multiple pieces of information scattered across a document to test the sequential processing and recall abilities of LLMs.
- ...
- Counter-Example(s):
- Standard Retrieval Measures, which focus on overall correctness without necessarily accounting for the ability to retrieve specific, deeply embedded details in large datasets.
- See: Large Language Model, Performance Metric, Precision and Recall Metrics, LLM In-Context Recall Measure, Information Retrieval.
References
2023
- https://twitter.com/GregKamradt/status/1722386725635580292?lang=en
- QUOTE:
- NOTES:
- **Recall Performance Degradation**: GPT-4’s ability to accurately recall information begins to decline when the context exceeds 73,000 tokens, suggesting a limit to the model's effectiveness in managing very large datasets.
- **Impact of Fact Placement**: The placement of facts within a document significantly affects recall accuracy. Facts located in the first 7%-50% of the document show decreased recall performance, whereas facts at the very beginning or in the second half of the document are recalled more reliably.
- **Document Depth and Context Length**: The test results indicate that both the depth at which the information is placed and the total length of the context are crucial factors. Shorter contexts tend to enhance recall accuracy, supporting the principle that less context can result in more precise information retrieval.
- **Testing Methodology**: The study utilized a unique methodology where facts were embedded at various depths within Paul Graham essays, simulating real-world scenarios of information retrieval across documents of varying lengths up to 128,000 tokens.
- **Suggestions for Application Development**: Developers are advised not to assume guaranteed retrieval of facts by LLMs in their applications, especially in contexts where precision is critical. Instead, strategies should consider optimizing the amount of contextual information and the positioning of key facts to improve recall outcomes.
- QUOTE: