Apache Spark Driver-Worker System Architecture
(Redirected from Apache Spark System Architecture)
Jump to navigation
Jump to search
An Apache Spark Driver-Worker System Architecture is a driver-worker software-based system architecture for an Apache Spark.
- Context:
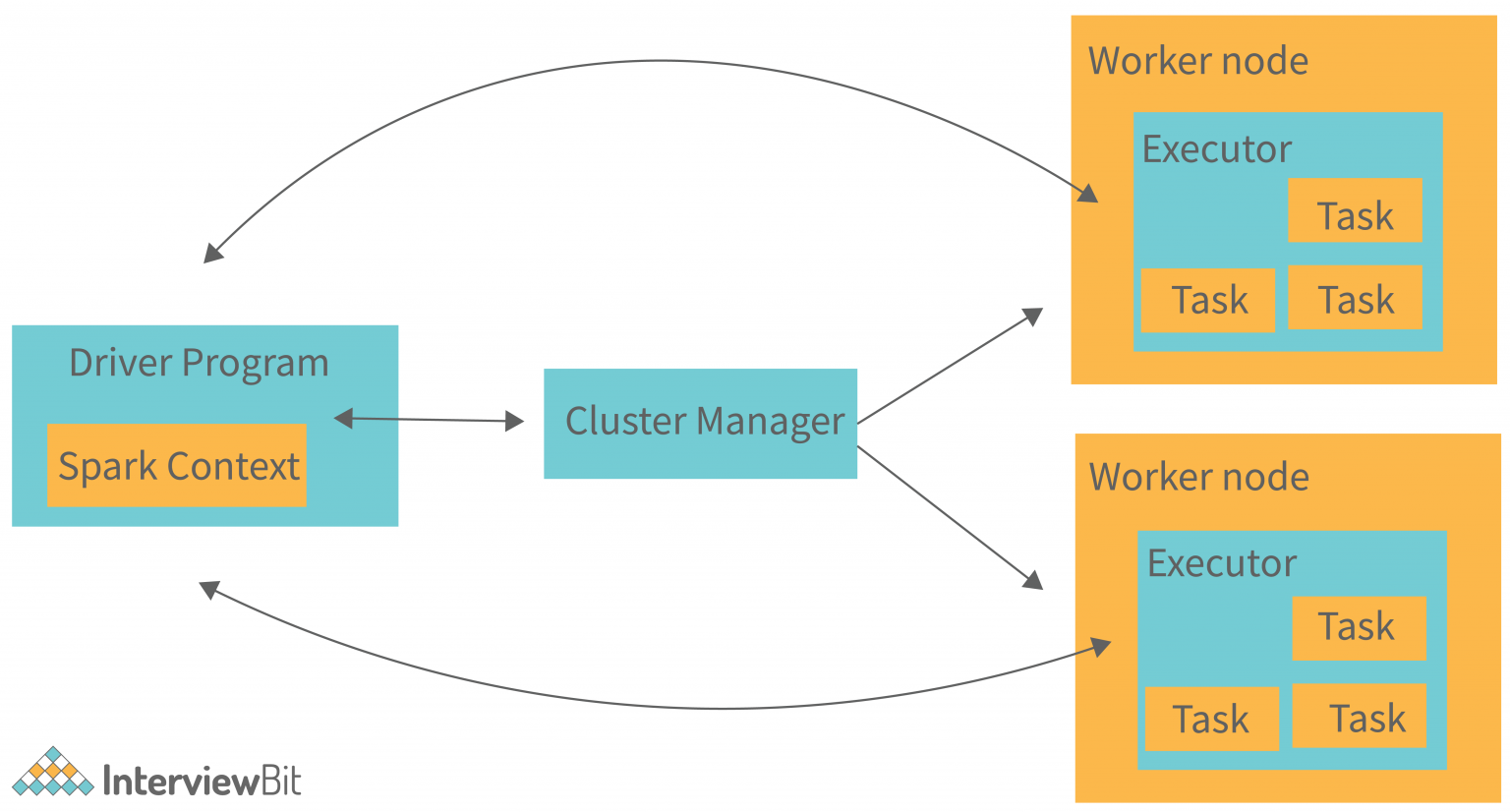
- It can (typically) consist of Spark Driver (which runs as a master node).
- It can (typically) consist of many Spark Executors (that run across as worker nodes in the cluster).
- …
- Example(s):
- …
- See: Map-Reduce Architecture.
References
2023
- chat
- Apache Spark is an open-source, distributed computing system designed for fast and large-scale data processing. Its architecture is based on the concepts of Resilient Distributed Datasets (RDDs) and Directed Acyclic Graph (DAG) execution engine. The core components of Apache Spark's architecture are:
- Driver Program: The driver program runs the main function and is responsible for coordinating tasks across the cluster. It defines one or more SparkContext objects, which are the main entry points for interacting with Spark's execution engine.
- SparkContext: SparkContext is the central coordinator for Spark applications. It communicates with the cluster manager to allocate resources and schedule tasks. SparkContext also manages caching and distributed storage of RDDs.
- Cluster Manager: The cluster manager is responsible for managing resources and scheduling tasks across the cluster. Spark can work with various cluster managers like standalone, Apache Mesos, Hadoop YARN, and Kubernetes.
- Executor: Executors are JVM processes running on worker nodes that execute tasks scheduled by the driver program. Each executor runs multiple tasks concurrently in separate threads and communicates directly with the driver program to report the status of the tasks. Executors are also responsible for caching RDD partitions in memory or on disk.
- Task: A task is the smallest unit of work in Spark, representing a single operation on a partition of data. Tasks are bundled into stages, which are groups of tasks with the same operation and dependencies.
- RDD (Resilient Distributed Dataset): RDD is an immutable, distributed collection of objects that can be processed in parallel. RDDs are partitioned across the nodes of the cluster, and Spark automatically handles their distribution, fault tolerance, and recovery.
- DAG Scheduler: The DAG scheduler divides a Spark application into stages based on dependencies between RDDs. It schedules tasks on the executor nodes, taking into account data locality and cluster resources.
- Query Execution: Spark's Catalyst query optimizer and Tungsten execution engine optimize and execute SQL queries and DataFrame/Dataset operations. Catalyst optimizes query plans using techniques like predicate pushdown and projection pruning, while Tungsten optimizes physical execution using techniques like code generation and memory management.
- Apache Spark is an open-source, distributed computing system designed for fast and large-scale data processing. Its architecture is based on the concepts of Resilient Distributed Datasets (RDDs) and Directed Acyclic Graph (DAG) execution engine. The core components of Apache Spark's architecture are:
2022
- https://interviewbit.com/blog/apache-spark-architecture/
- QUOTE: ... The Apache Spark base architecture diagram is provided in the following figure:
- QUOTE: ... The Apache Spark base architecture diagram is provided in the following figure: