Apache Spark Job
A Apache Spark Job is a distributed data-processing job that can run on a Spark cluster (based on a Spark framework).
- Context:
- It can (typically) be an instance of a SparkContext.
- It can access Spark Entry Points.
- It can range from being a Python Spark Job to being a Scala Spark Job to being a R Spark Job to being a SQL Spark Job.
- It can range from being a Successful Spark Job to being a Failed Spark Job.
- It can be associated with a Spark Execution Plan.
- It can be associated with a Spark Job Unit Test.
- …
- Example(s):
- Counter-Example(s):
- a Map/Reduce Job, such as an Apache Pig Job.
- a Scalding Job[1].
- See: Spark-based Application, Spark Action, SparkSession, Spark Cassandra Connector.
References
2018
- Ashkrit Sharma. (2018). “Anatomy of Apache Spark Job.” Blog post
- QUOTE: ... Spark is using lazy evaluation paradigm in which Spark application does not anything till driver calls “Action”. ... Spark application is made up of jobs, stages & tasks. Jobs & tasks are executed in parallel by spark but stage inside job are sequential. Knowing what executes parallel and sequence is very important when you want to tune spark jobs.
Stages are executed in order, so job with many stages will choke on it and also previous stages will feed next stages and it comes with some overhead that involves writing stages output to persistent source (i.e disk, hdfs, s3 etc) and reading it again. This is also called wide transformation/Shuffle dependency.
Job with single stage will be very fast but you can’t build any useful application using single stage. ...
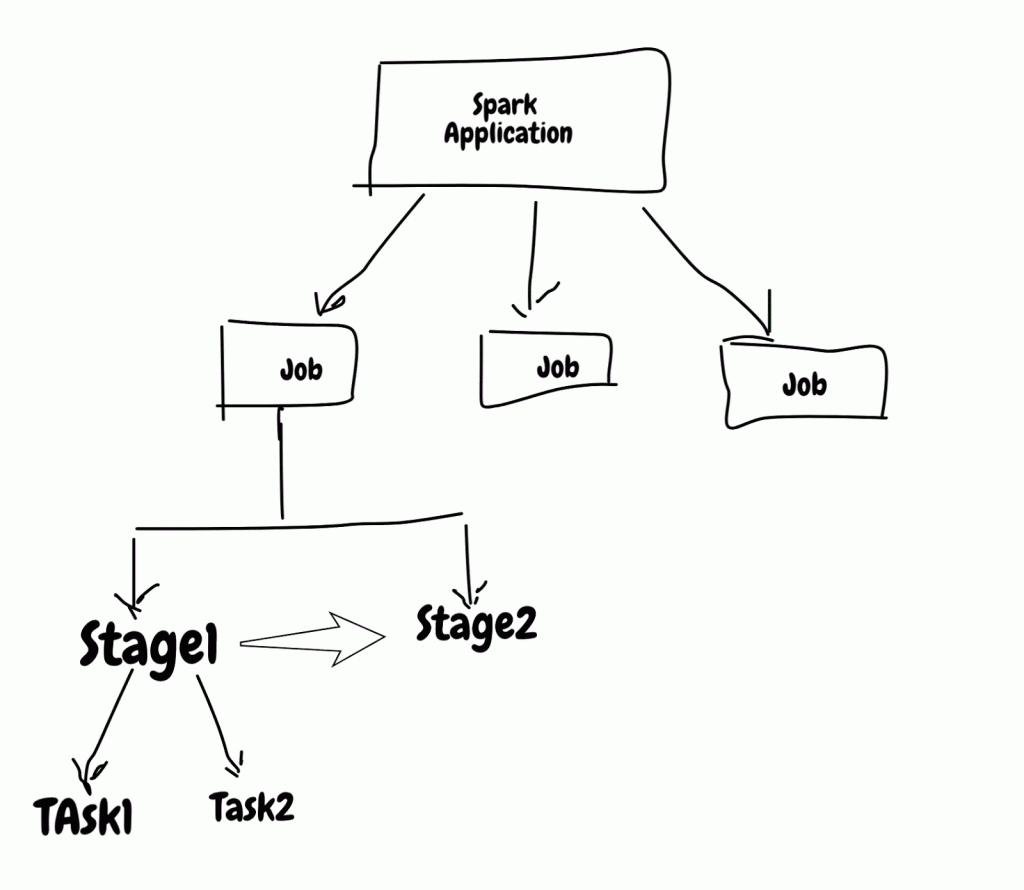
- QUOTE: ... Spark is using lazy evaluation paradigm in which Spark application does not anything till driver calls “Action”. ... Spark application is made up of jobs, stages & tasks. Jobs & tasks are executed in parallel by spark but stage inside job are sequential. Knowing what executes parallel and sequence is very important when you want to tune spark jobs.
2017
- https://spark.apache.org/docs/2.1.0/programming-guide.html
- QUOTE: At a high level, every Spark application consists of a driver program that runs the user’s main function and executes various parallel operations on a cluster. The main abstraction Spark provides is a resilient distributed dataset (RDD), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in parallel. RDDs are created by starting with a file in the Hadoop file system (or any other Hadoop-supported file system), or an existing Scala collection in the driver program, and transforming it. Users may also ask Spark to persist an RDD in memory, allowing it to be reused efficiently across parallel operations. Finally, RDDs automatically recover from node failures.
A second abstraction in Spark is shared variables that can be used in parallel operations. By default, when Spark runs a function in parallel as a set of tasks on different nodes, it ships a copy of each variable used in the function to each task. Sometimes, a variable needs to be shared across tasks, or between tasks and the driver program. Spark supports two types of shared variables: broadcast variables, which can be used to cache a value in memory on all nodes, and accumulators, which are variables that are only “added” to, such as counters and sums.
- QUOTE: At a high level, every Spark application consists of a driver program that runs the user’s main function and executes various parallel operations on a cluster. The main abstraction Spark provides is a resilient distributed dataset (RDD), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in parallel. RDDs are created by starting with a file in the Hadoop file system (or any other Hadoop-supported file system), or an existing Scala collection in the driver program, and transforming it. Users may also ask Spark to persist an RDD in memory, allowing it to be reused efficiently across parallel operations. Finally, RDDs automatically recover from node failures.
2016
- http://www.cloudera.com/documentation/enterprise/5-6-x/topics/cdh_ig_spark_apps.html
- QUOTE: Spark application execution involves runtime concepts such as driver, executor, task, job, and stage. Understanding these concepts is vital for writing fast and resource efficient Spark programs.
At runtime, a Spark application maps to a single driver process and a set of executor processes distributed across the hosts in a cluster.
The driver process manages the job flow and schedules tasks and is available the entire time the application is running. Typically, this driver process is the same as the client process used to initiate the job, although when run on YARN, the driver can run in the cluster. In interactive mode, the shell itself is the driver process.
The executors are responsible for executing work, in the form of tasks, as well as for storing any data that you cache. Executor lifetime depends on whether dynamic allocation is enabled. An executor has a number of slots for running tasks, and will run many concurrently throughout its lifetime.
Invoking an action inside a Spark application triggers the launch of a job to fulfill it. Spark examines the dataset on which that action depends and formulates an execution plan. The execution plan assembles the dataset transformations into stages. A stage is a collection of tasks that run the same code, each on a different subset of the data.

- QUOTE: Spark application execution involves runtime concepts such as driver, executor, task, job, and stage. Understanding these concepts is vital for writing fast and resource efficient Spark programs.
2015
- https://spark.apache.org/docs/latest/job-scheduling.html
- QUOTE: Spark has several facilities for scheduling resources between computations. First, recall that, as described in the cluster mode overview, each Spark application (instance of SparkContext) runs an independent set of executor processes. The cluster managers that Spark runs on provide facilities for scheduling across applications. Second, within each Spark application, multiple “jobs” (Spark actions) may be running concurrently if they were submitted by different threads. This is common if your application is serving requests over the network. Spark includes a fair scheduler to schedule resources within each SparkContext.