Statistical Linguistic Translation (MT) System
(Redirected from statistical machine translation (SMT))
A Statistical Linguistic Translation (MT) System is a data-driven MT system that is a statistical NLP system.
- AKA: Statistical Machine Translation (SMT) System.
- Context:
- It can solve a statistical MT task by implementing a statistical MT algorithm.
- It can range from being a Rule-based Statistical Machine Translation System to being an Example-based Statistical Machine Translation System.
- It can range from being an Automatic Text Translation System to being an Automatic Speech Translation System.
- Example(s):
- Counter-Example(s):
- See: Machine Translation Algorithm, Language Model.
References
2020
- (Wikipedia, 2020) ⇒ https://en.wikipedia.org/wiki/Statistical_machine_translation Retrieved:2020-9-14.
- Statistical machine translation (SMT) is a machine translation paradigm where translations are generated on the basis of statistical models whose parameters are derived from the analysis of bilingual text corpora. The statistical approach contrasts with the rule-based approaches to machine translation as well as with example-based machine translation. The first ideas of statistical machine translation were introduced by Warren Weaver in 1949, [1] including the ideas of applying Claude Shannon's information theory. Statistical machine translation was re-introduced in the late 1980s and early 1990s by researchers at IBM's Thomas J. Watson Research Center[2] [3] [4] and has contributed to the significant resurgence in interest in machine translation in recent years. Before the introduction of neural machine translation, it was by far the most widely studied machine translation method.
- ↑ W. Weaver (1955). Translation (1949). In: Machine Translation of Languages, MIT Press, Cambridge, MA.
- ↑ P. Brown; John Cocke, S. Della Pietra, V. Della Pietra, Frederick Jelinek, Robert L. Mercer, P. Roossin (1988). "A statistical approach to language translation". Coling'88.
- ↑ P. Brown; John Cocke, S. Della Pietra, V. Della Pietra, Frederick Jelinek, John D. Lafferty, Robert L. Mercer, P. Roossin (1990). "A statistical approach to machine translation". Computational Linguistics. MIT Press. 16 (2): 79–85. Retrieved 22 March 2015.
- ↑ P. Brown; S. Della Pietra, V. Della Pietra, and R. Mercer (1993). "The mathematics of statistical machine translation: parameter estimation". Computational Linguistics. MIT Press. 19 (2): 263–311. Retrieved 22 March 2015.
2020
- http://www.statmt.org/moses/?n=Moses.Background
- QUOTE: MOSES ... The figure below illustrates the process of phrase-based translation. The input is segmented into a number of sequences of consecutive words (so-called phrases). Each phrase is translated into an English phrase, and English phrases in the output may be reordered.
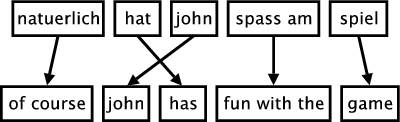
In this section, we will define the phrase-based machine translation model formally. The phrase translation model is based on the noisy channel model. We use Bayes rule to reformulate the translation probability for translating a foreign sentence f into English e as [math]\displaystyle{ argmax_{e} p(e|f) = argmax_{e} p(f|e) p(e) }[/math] ...
- QUOTE: MOSES ... The figure below illustrates the process of phrase-based translation. The input is segmented into a number of sequences of consecutive words (so-called phrases). Each phrase is translated into an English phrase, and English phrases in the output may be reordered.
2016
- (Junczys-Dowmunt & Grundkiewicz, 2016) ⇒ Marcin Junczys-Dowmunt, and Roman Grundkiewicz. (2016). “Phrase-based Machine Translation is State-of-the-Art for Automatic Grammatical Error Correction.” In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP 2016).
2007
- (Koehn et al., 2007) ⇒ Philipp Koehn, Hieu Hoang, Alexandra Birch, Chris Callison-Burch, Marcello Federico, Nicola Bertoldi, Brooke Cowan, Wade Shen, Christine Moran, Richard Zens, Chris Dyer, Ondrej Bojar, Alexandra Constantin, and Evan Herbst. (2007). “Moses: Open Source Toolkit for Statistical Machine Translation". In: Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics Companion Volume Proceedings of the Demo and Poster Sessions (ACL 2007).
- QUOTE: Phrase-based statistical machine translation (Koehn et al. 2003) has emerged as the dominant paradigm in machine translation research. However, until now, most work in this field has been carried out on proprietary and in-house research systems. This lack of openness has created a high barrier to entry for researchers as many of the components required have had to be duplicated. This has also hindered effective comparisons of the different elements of the systems.
2003
- (Koehn et al., 2003) ⇒ Philipp Koehn, Franz Josef Och, and Daniel Marcu. (2003). “Statistical Phrase-Based Translation". In: Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics (HLT-NAACL 2003).
- QUOTE: We propose a new phrase-based translation model and decoding algorithm that enables us to evaluate and compare several, previously proposed phrase-based translation models.