Character-Level Neural Sequence-to-Sequence (seq2seq) Model Training Algorithm
(Redirected from character-level seq2seq)
Jump to navigation
Jump to search
A Character-Level Neural Sequence-to-Sequence (seq2seq) Model Training Algorithm is a seq2seq algorithm that is a character-level NNet algorithm.
- Context:
- It can be implemented by a Character-Level Seq2Seq System that can solve a Character-Level Seq2Seq Task which produces a Character-Level Seq2Seq Model.
- It can make use of Character Embeddings.
- Example(s):
- Counter-Example(s):
- See: Natural Language Processing Algorithm, Neural Translation Algorithm, Sequence-To-Sequence Neural Network, Neural Network Training System, Parsing Algorithm, Text Processing System, Computer Character, Text Error Correction System.
References
2016a
- (Barzdins & Gosko, 2016) ⇒ Guntis Barzdins, and Didzis Gosko. (2016). “RIGA at SemEval-2016 Task 8: Impact of Smatch Extensions and Character-Level Neural Translation on AMR Parsing Accuracy.” In: Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), pp. 1143-1147.
- QUOTE: Operating seq2seq model on the character-level (Karpathy, 2015; Chung et al., 2016; Luong et al., 2016) rather than standard word-level improved smatch F1 by notable 7%.
Follow-up tests (Barzdins et al., 2016) revealed that character-level translation with attention improves results only if the output is a syntactic variation of the input …
- QUOTE: Operating seq2seq model on the character-level (Karpathy, 2015; Chung et al., 2016; Luong et al., 2016) rather than standard word-level improved smatch F1 by notable 7%.
2016b
- (Hewlett et al., 2016) ⇒ Daniel Hewlett, Alexandre Lacoste, Llion Jones, Illia Polosukhin, Andrew Fandrianto, Jay Han, Matthew Kelcey, and David Berthelot. (2016). “WikiReading: A Novel Large-scale Language Understanding Task over Wikipedia.” In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL-2016).
- QUOTE: ... Another way of handling rare words is to process the input and output text as sequences of characters or bytes. RNNs have shown some promise working with character-level input, including state-of-the-art performance on a Wikipedia text classification benchmark (Dai and Le, 2015). A model that outputs answers character by character can in principle generate any of the answers in the test set, a major advantage for WIKIREADING ... Character seq2seq model. Blocks with the same color share parameters. ...

- QUOTE: ... Another way of handling rare words is to process the input and output text as sequences of characters or bytes. RNNs have shown some promise working with character-level input, including state-of-the-art performance on a Wikipedia text classification benchmark (Dai and Le, 2015). A model that outputs answers character by character can in principle generate any of the answers in the test set, a major advantage for WIKIREADING ... Character seq2seq model. Blocks with the same color share parameters. ...
2015
- (Karpathy, 2015) ⇒ Andrej Karpathy. (2015). “The Unreasonable Effectiveness of Recurrent Neural Networks.” In: Blog post 2015-05-21.
- QUOTE:
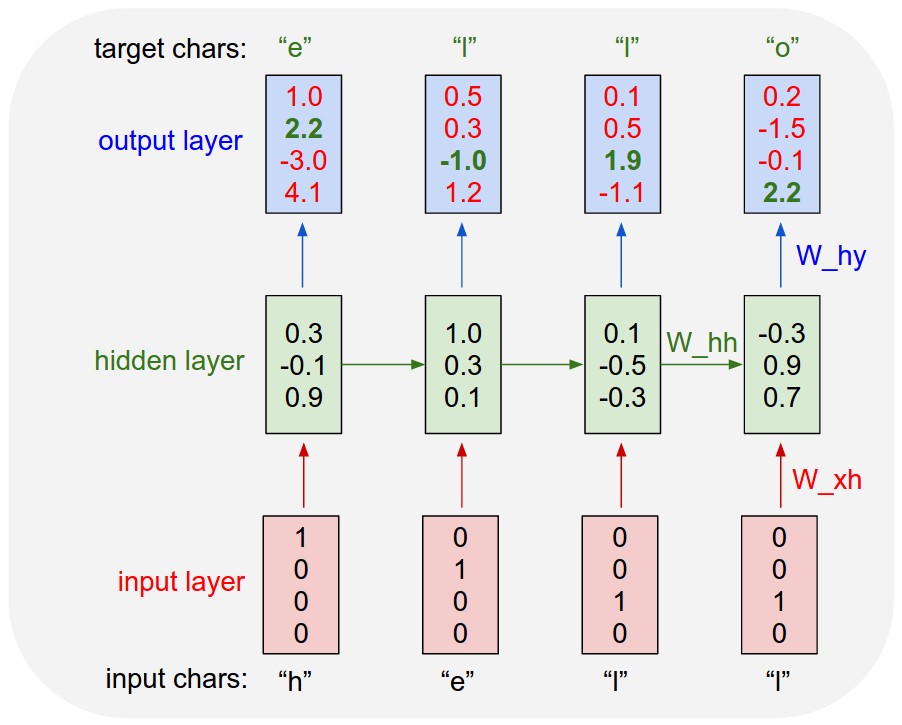
An example RNN with 4-dimensional input and output layers, and a hidden layer of 3 units (neurons). This diagram shows the activations in the forward pass when the RNN is fed the characters "hell" as input. The output layer contains confidences the RNN assigns for the next character (vocabulary is "h,e,l,o"); We want the green numbers to be high and red numbers to be low.
- QUOTE: