Bidirectional LSTM (BiLSTM) Model
(Redirected from bidirectional variant of LSTM, (BLSTM))
Jump to navigation
Jump to search
A Bidirectional LSTM (BiLSTM) Model is an LSTM network that is a bidirectional RNN network.
- Context:
- It can be trained by a Bidirectional LSTM Training System (that implements a BiLSTM training algorithm).
- It can range from being a Shallow BiLSTM Network to being a Deep BiLSTM Network.
- …
- Example(s):
- a BiLSTM-CNN, such as a BiLSTM-CNN-CRF.
- a BiLSTM-CRF, such as a BiLSTM-CNN-CRF.
- a BiLSTM WSD Classifier.
- a Self-Attention Bi-LSTM.
- …
- Counter-Example(s)
- See: LSTM, RNN, Bidirectional RNN, GRU, Attention Mechanism.
References
2018a
- (Cui et al., 2018) ⇒ Zhiyong Cui, Ruimin Ke, and Yinhai Wang. (2018). “Deep Bidirectional and Unidirectional LSTM Recurrent Neural Network for Network-wide Traffic Speed Prediction.” arXiv preprint arXiv:1801.02143
- QUOTE:
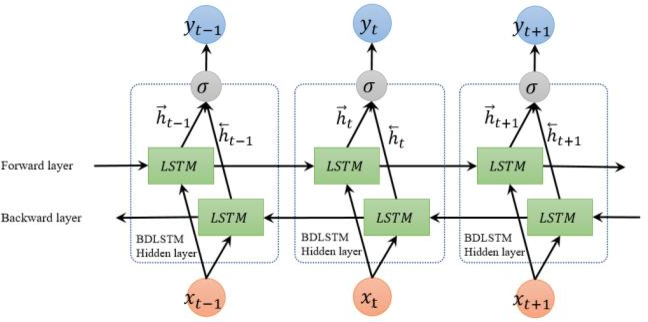
- QUOTE:
2018b
- (Ullah et al., 2018) ⇒ Amin Ullah, Jamil Ahmad, Khan Muhammad, Muhammad Sajjad, and Sung Wook Baik. (2018). "Action recognition in video sequences using deep Bi-directional LSTM with CNN features." IEEE Access, 6, 1155-1166.
- QUOTE: The procedure for action recognition is divided into two parts: First, we extract CNN features from the frames of video [math]\displaystyle{ V_I }[/math] with jump [math]\displaystyle{ J_F }[/math] in sequence of frames such that the jump [math]\displaystyle{ J_F }[/math] does not affect the sequence of the action [math]\displaystyle{ A_I }[/math] in the video. Second, the features representing the sequence of action [math]\displaystyle{ A_I }[/math] for time interval [math]\displaystyle{ T_S }[/math] (such as [math]\displaystyle{ T_S=1 }[/math] sec) are fed to the proposed DB-LSTM in [math]\displaystyle{ C_N }[/math] chunks, where each [math]\displaystyle{ C_I }[/math] chunk is the features representation of the video frame and input to one RNN step. At the end, the final state of each time internal [math]\displaystyle{ T_S }[/math] is analyzed for final recognition of an action in a video. The proposed framework is shown in Fig. 1.

FIGURE 1. Framework of the proposed DB-LSTM for action recognition
- QUOTE: The procedure for action recognition is divided into two parts: First, we extract CNN features from the frames of video [math]\displaystyle{ V_I }[/math] with jump [math]\displaystyle{ J_F }[/math] in sequence of frames such that the jump [math]\displaystyle{ J_F }[/math] does not affect the sequence of the action [math]\displaystyle{ A_I }[/math] in the video. Second, the features representing the sequence of action [math]\displaystyle{ A_I }[/math] for time interval [math]\displaystyle{ T_S }[/math] (such as [math]\displaystyle{ T_S=1 }[/math] sec) are fed to the proposed DB-LSTM in [math]\displaystyle{ C_N }[/math] chunks, where each [math]\displaystyle{ C_I }[/math] chunk is the features representation of the video frame and input to one RNN step. At the end, the final state of each time internal [math]\displaystyle{ T_S }[/math] is analyzed for final recognition of an action in a video. The proposed framework is shown in Fig. 1.
2017a
- (Zeyer et al., 2017) ⇒ Albert Zeyer, Patrick Doetsch, Paul Voigtlaender, Ralf Schlüter, and Hermann Ney (2017, March). "A comprehensive study of deep bidirectional LSTM RNNs for acoustic modeling in speech recognition" (PDF). In Acoustics, Speech and Signal Processing (ICASSP), 2017 IEEE International Conference on (pp. 2462-2466). IEEE.
- ABSTRACT: Recent experiments show that deep bidirectional long short-term memory (BLSTM) recurrent neural network acoustic models outperform feedforward neural networks for automatic speech recognition (ASR). However, their training requires a lot of tuning and experience. In this work, we provide a comprehensive overview over various BLSTM training aspects and their interplay within ASR, which has been missing so far in the literature. We investigate on different variants of optimization methods, batching, truncated backpropagation, and regularization techniques such as dropout, and we study the effect of size and depth, training models of up to 10 layers. This includes a comparison of computation times vs. recognition performance. Furthermore, we introduce a pretraining scheme for LSTMs with layer-wise construction of the network showing good improvements especially for deep networks. The experimental analysis mainly was performed on the Quaero task, with additional results on Switchboard. The best BLSTM model gave a relative improvement in word error rate of over 15% compared to our best feed-forward baseline on our Quaero 50h task. All experiments were done using RETURNN and RASR, RWTH's extensible training framework for universal recurrent neural networks and ASR toolkit. The training configuration files are publicly available.
2017b
- (Luo et al. 2017) ⇒ Yuan Luo, Yu Liu, Yi Zhang, Boyu Wang, and Zhou Ye (2017, December). "Maxout neurons based deep bidirectional LSTM for acoustic modeling". In Robotics and Biomimetics (ROBIO), 2017 IEEE International Conference on (pp. 1599-1604). IEEE.
- ABSTRACT: Recently long short-term memory (LSTM) recurrent neural networks (RNN) have achieved greater success in acoustic models for the large vocabulary continuous speech recognition system. In this paper, we propose an improved hybrid acoustic model based on deep bidirectional long short-term memory (DBLSTM) RNN. In this new acoustic model, maxout neurons are used in the fully-connected part of DBLSTM to solve the problems of vanishing and exploding gradient. At the same time, the dropout regularization algorithm is used to avoid the over-fitting during the training process of neural network. In addition, in order to adapt the bidirectional dependence of DBLSTM at each time step, a context-sensitive-chunk (CSC) back-propagation through time (BPTT) algorithm is proposed to train DBLSTM neural network. Simulation experiments have been made on Switchboard benchmark task. The results show that the WER of the improved hybrid acoustic model is 14.5%, and the optimal network structures and CSC configurations are given.
2016a
- (Chiu & Nichols, 2016) ⇒ Jason Chiu, and Eric Nichols. (2016). “Named Entity Recognition with Bidirectional LSTM-CNNs.” In: Transactions of the Association of Computational Linguistics, 4(1).
- QUOTE: … In this paper, we present a novel neural network architecture that automatically detects word- and character-level features using a hybrid bidirectional LSTM and CNN architecture, eliminating the need for most feature engineering. …
2016b
- (Kågebäck & Salomonsson, 2016) ⇒ Mikael Kågebäck, and Hans Salomonsson. (2016). “Word Sense Disambiguation Using a Bidirectional LSTM.” In: Proceedings of COLING 2016 (COLING 2016).
- QUOTE: Long short-term memory (LSTM) is a gated type of recurrent neural network (RNN). LSTMs were introduced by Hochreiter and Schmidhuber (1997) to enable RNNs to better capture long term dependencies when used to model sequences. This is achieved by letting the model copy the state between timesteps without forcing the state through a non-linearity. The flow of information is instead regulated using multiplicative gates which preserves the gradient better than e.g. the logistic function. The bidirectional variant of LSTM, (BLSTM) (Graves and Schmidhuber, 2005) is an adaptation of the LSTM where the state at each time step consist of the state of two LSTMs, one going left and one going right. For WSD this means that the state has information about both preceding words and succeeding words, which in many cases are absolutely necessary to correctly classify the sense.
2015a
- (Fan et al., 2015) ⇒ Bo Fan, Lijuan Wang, Frank K. Soong, and Lei Xie (2015, April). "Photo-real talking head with deep bidirectional LSTM". In Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on (pp. 4884-4888). IEEE. DOI: 10.1109/ICASSP.2015.7178899
- QUOTE: In our BLSTM network, as shown in Fig. 3, label sequence [math]\displaystyle{ L }[/math] is the input layer, and visual feature sequence [math]\displaystyle{ V }[/math] serves as the output layer and [math]\displaystyle{ H }[/math] denotes the hidden layer. In particular, at t-th frame, the input of the network is the t-th label vector [math]\displaystyle{ l_t }[/math] and the output is the [math]\displaystyle{ t }[/math]-th visual feature vector [math]\displaystyle{ v_t }[/math]. As described in (Graves, 2012), the basic idea of this bidirectional structure is to present each sequence forwards and backwards to two separate recurrent hidden layers, both of which are connected to the same output layer.

Fig. 3. BLSTM neural network in our talking head system.
- QUOTE: In our BLSTM network, as shown in Fig. 3, label sequence [math]\displaystyle{ L }[/math] is the input layer, and visual feature sequence [math]\displaystyle{ V }[/math] serves as the output layer and [math]\displaystyle{ H }[/math] denotes the hidden layer. In particular, at t-th frame, the input of the network is the t-th label vector [math]\displaystyle{ l_t }[/math] and the output is the [math]\displaystyle{ t }[/math]-th visual feature vector [math]\displaystyle{ v_t }[/math]. As described in (Graves, 2012), the basic idea of this bidirectional structure is to present each sequence forwards and backwards to two separate recurrent hidden layers, both of which are connected to the same output layer.

2015b
- (Huang, Xu & Yu, 2015) ⇒ Zhiheng Huang, Wei Xu, Kai Yu (2015). "Bidirectional LSTM-CRF models for sequence tagging (PDF)". arXiv preprint arXiv:1508.01991.
- QUOTE: In sequence tagging task, we have access to both past and future input features for a given time, we can thus utilize a bidirectional LSTM network (Figure 4) as proposed in (Graves et al., 2013). In doing so, we can efficiently make use of past features (via forward states) and future features (via backward states) for a specific time frame. We train bidirectional LSTM networks using backpropagation through time (BPTT)(Boden., 2002). The forward and backward passes over the unfolded network over time are carried out in a similar way to regular network forward and backward passes, except that we need to unfold the hidden states for all time steps. We also need a special treatment at the beginning and the end of the data points. In our implementation, we do forward and backward for whole sentences and we only need to reset the hidden states to 0 at the begging of each sentence. We have batch implementation which enables multiple sentences to be processed at the same time. .

Figure 4: A bidirectional LSTM network.
- QUOTE: In sequence tagging task, we have access to both past and future input features for a given time, we can thus utilize a bidirectional LSTM network (Figure 4) as proposed in (Graves et al., 2013). In doing so, we can efficiently make use of past features (via forward states) and future features (via backward states) for a specific time frame. We train bidirectional LSTM networks using backpropagation through time (BPTT)(Boden., 2002). The forward and backward passes over the unfolded network over time are carried out in a similar way to regular network forward and backward passes, except that we need to unfold the hidden states for all time steps. We also need a special treatment at the beginning and the end of the data points. In our implementation, we do forward and backward for whole sentences and we only need to reset the hidden states to 0 at the begging of each sentence. We have batch implementation which enables multiple sentences to be processed at the same time.

2013
- (Graves, Jaitly, & Mohamed, 2013) ⇒ Alex Graves, Navdeep Jaitly, and Abdel-rahman Mohamed (2013, December). "Hybrid speech recognition with deep bidirectional LSTM" (PDF). In Automatic Speech Recognition and Understanding (ASRU), 2013 IEEE Workshop on (pp. 273-278). IEEE.
- ABSTRACT: Deep Bidirectional LSTM (DBLSTM) recurrent neural networks have recently been shown to give state-of-the-art performance on the TIMIT speech database. However, the results in that work relied on recurrent-neural-network-specific objective functions, which are difficult to integrate with existing large vocabulary speech recognition systems. This paper investigates the use of DBLSTM as an acoustic model in a standard neural network-HMM hybrid system. We find that a DBLSTM-HMM hybrid gives equally good results on TIMIT as the previous work. It also outperforms both GMM and deep network benchmarks on a subset of the Wall Street Journal corpus. However the improvement in word error rate over the deep network is modest, despite a great increase in frame level accuracy. We conclude that the hybrid approach with DBLSTM appears to be well suited for tasks where acoustic modelling predominates. Further investigation needs to be conducted to understand how to better leverage the improvements in frame-level accuracy towards better word error rates.
2005a
- (Graves, Fernandez & Schmidhuber, 2005) ⇒ Alex Graves, Santiago Fernandez, and Jurgen Schmidhuber (2005). "Bidirectional LSTM networks for improved phoneme classification and recognition" (PDF). In: Proceedings of The International Conference on Artificial Neural Networks (pp. 799-804). Springer, Berlin, Heidelberg.
- QUOTE: In this paper, we extend our previous work on bidirectional LSTM (BLSTM) (Graves & Schmidhuber, 2005) with experiments on both framewise phoneme classification and phoneme recognition. For phoneme recognition we use the hybrid approach, combining Hidden Markov Models (HMMs) and RNNs in an iterative training procedure (see Section 3). This gives us an insight into the likely impact of bidirectional training on speech recognition, and also allows us to compare our results directly with a traditional HMM system.
2005b
- (Graves & Schmidhuber, 2005) ⇒ Alex Graves, and Jürgen Schmidhuber (2005). "Framewise phoneme classification with bidirectional LSTM and other neural network architectures" (PDF). Neural Networks, 18(5-6), 602-610.
- ABSTRACT: In this paper, we present bidirectional Long Short Term Memory (LSTM) networks, and a modified, full gradient version of the LSTM learning algorithm. We evaluate Bidirectional LSTM (BLSTM) and several other network architectures on the benchmark task of framewise phoneme classification, using the TIMIT database. Our main findings are that bidirectional networks outperform unidirectional ones, and Long Short Term Memory (LSTM) is much faster and also more accurate than both standard Recurrent Neural Nets (RNNs) and time-windowed Multilayer Perceptrons (MLPs). Our results support the view that contextual information is crucial to speech processing, and suggest that BLSTM is an effective architecture with which to exploit it.