Vespa Platform
A Vespa Platform is a distributed real-time document DBMS.
- See: ElasticSearch, Hadoop.
References
2017a
- http://docs.vespa.ai/documentation/features.html
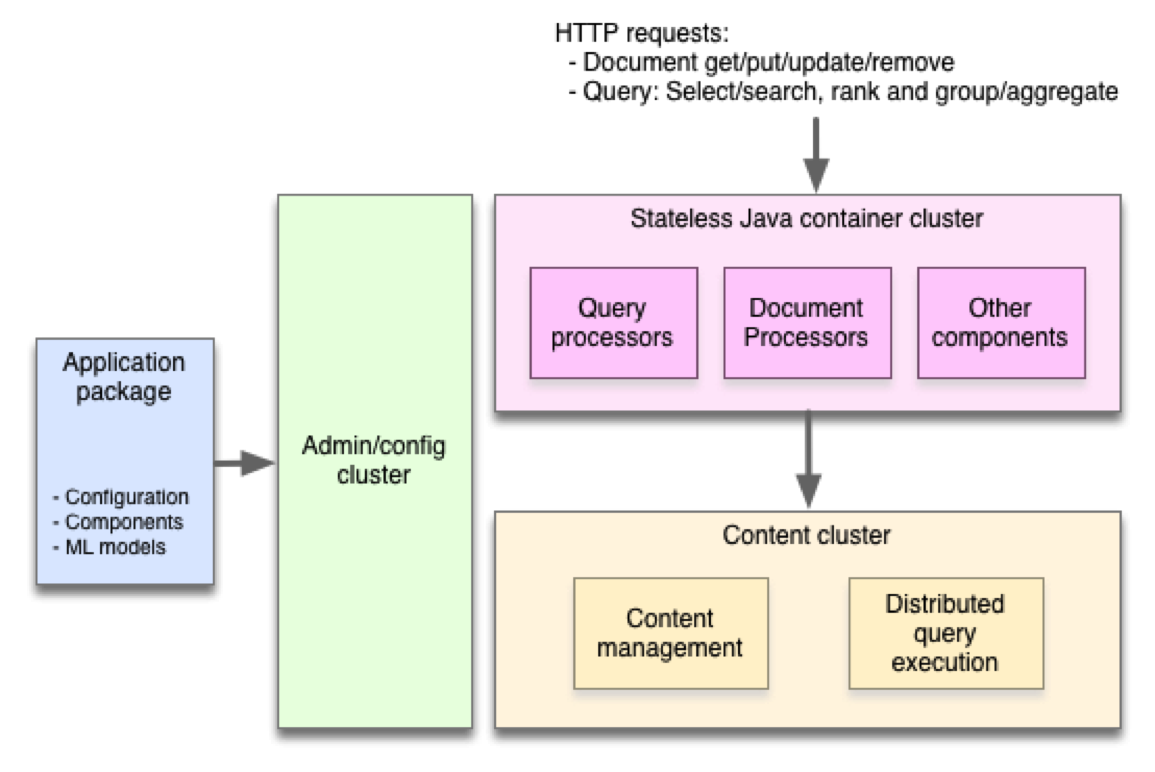
- QUOTE: Vespa is an engine for executing and serving computations over large data sets in real time. It allows you to write and persist any amount of data, and execute high volumes of queries over the data which typically complete in tens of milliseconds.
Queries can use both structured filters and unstructured text search to select data. All the matching data is then ranked according to a ranking function - typically machine learned - to implement such use cases as search relevance, recommendation, targeting and personalization.
All the matching data can also be grouped into groups and subgroups where data is aggregated for each group to implement features like graphs, tag clouds, navigational tools, result diversity and so on.
Application specific behavior can be included by adding Java components for processing queries, results and writes to the application package.
Vespa is real time. It is architected to maintain constant response times with any data volume by executing queries in parallel over many data shards and cores, and with added query volume by executing queries in parallel over many copies of the same data (groups). It is optimized to return responses in tens of milliseconds. Writes to data becomes visible in a few milliseconds and can be handled at a rate of thousands to tens of thousands per node per second.
A lot of work has gone into making Vespa easy to set up and operate. Any Vespa application - from single node systems to systems running on hundreds of nodes in data centers - are fully configured by a single artifact called an application package. Low level configuration of nodes, processes and components is done by the system itself based on the desired traits specified in the application package.
Vespa is scalable. System sizes up to hundreds of nodes handling tens of billions of documents are not uncommon, and no harder to set up and modify than single node systems. Since all system components, as well as stored data is redundant and self-correcting, hardware failures are not operational emergencies and can be handled by re-adding capacity when convenient.
Vespa is self-repairing and dynamic. When machines are lost or new ones added, data is automatically redistributed over the machines, while continuing serving and accepting writes to the data. Changes to configuration and Java components can be made while serving by deploying a changed application package - no down time or restarts required.
- QUOTE: Vespa is an engine for executing and serving computations over large data sets in real time. It allows you to write and persist any amount of data, and execute high volumes of queries over the data which typically complete in tens of milliseconds.
2017b
- http://oath.com/press/open-sourcing-vespa-yahoo-s-big-data-processing-and-serving-eng/
- QUOTE: With Vespa, our teams build applications that:
- Select content items using SQL-like queries and text search
- Organize all matches to generate data-driven pages.
- Rank matches by handwritten or machine-learned relevance models
- Serve results with response times in the lows milliseconds
- Write data in real-time, thousands of times per second per node
- Grow, shrink, and re-configure clusters while serving and writing data
- QUOTE: With Vespa, our teams build applications that: