VGG Convolutional Neural Network
(Redirected from VGG architecture)
Jump to navigation
Jump to search
A VGG Convolutional Neural Network is a Deep Convolutional Neural Network developed by the Visual Geometry Group (VGG), University of Oxford for the ImageNet Challenge.
- AKA: VGGNet.
- Context
- It can be produced by a VGG Training System that implements an VGG Algorithm to solve an VGG Training Task.
- It can solve the classification task of ILSVRC-2014 challenge.
- It ranges from being a 11-layer to being a 19-layer deep convolutional neural network.
- Example(s):
- Counter-Example(s):
- See: Convolution Function, Neural Network Layer, Neural Network Unit, Neural Network Convolutional Layer, Neural Network Pooling Layer, Neural Network Activation Function, Neural Network Weight, Artificial Neural Network, Supervised Machine Learning System, Machine Learning Classification System, Unsupervised Machine Learning System, Reiforcement Learning System, Deep Learning System.
References
2018a
- (Frossard, 2018) ⇒ Davi Frossard (2018). VGG in TensorFlow: https://www.cs.toronto.edu/~frossard/post/vgg16/ Retrieved:2018-07-29
- QUOTE: VGG is a convolutional neural network model proposed by K. Simonyan and A. Zisserman from the University of Oxford in the paper “Very Deep Convolutional Networks for Large-Scale Image Recognition” . The model achieves 92.7% top-5 test accuracy in ImageNet [2], which is a dataset of over 14 million images belonging to 1000 classes.
In this short post we provide an implementation of VGG16 and the weights from the original Caffe model[3] converted to TensorFlow[4].
Architecture
The macroarchitecture of VGG16 can be seen in Fig. 2. We code it in TensorFlow in file
vgg16.py. Notice that we include a preprocessing layer that takes the RGB image with pixels values in the range of 0-255 and subtracts the mean image values (calculated over the entire ImageNet training set).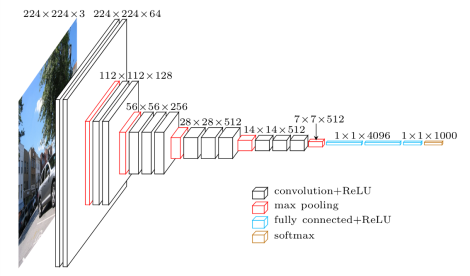
Fig.2: Macroarchitecture of VGG16 [5]
- QUOTE: VGG is a convolutional neural network model proposed by K. Simonyan and A. Zisserman from the University of Oxford in the paper “Very Deep Convolutional Networks for Large-Scale Image Recognition” . The model achieves 92.7% top-5 test accuracy in ImageNet [2], which is a dataset of over 14 million images belonging to 1000 classes.
2018b
- (VGG, 2018) ⇒ http://www.robots.ox.ac.uk/~vgg/research/very_deep/ Retrieved:2018-07-29
- QUOTE: The very deep ConvNets were the basis of our ImageNet ILSVRC-2014 submission, where our team (VGG) secured the first and the second places in the localisation and classification tasks respectively. After the competition, we further improved our models, which has lead to the following ImageNet classification results:

- QUOTE: The very deep ConvNets were the basis of our ImageNet ILSVRC-2014 submission, where our team (VGG) secured the first and the second places in the localisation and classification tasks respectively. After the competition, we further improved our models, which has lead to the following ImageNet classification results:
2018c
- (Mishra & Cheng, 2018) ⇒ Akshay Mishra, Hong Cheng (2017, 2018). Advanced CNN Architectures: http://slazebni.cs.illinois.edu/spring17/lec04_advanced_cnn.pdf Retrieved:2018-07-29
2018d
- (CS231N, 2018) ⇒ https://cs231n.github.io/convolutional-networks/#case Retrieved 2018-09-30
- QUOTE: There are several architectures in the field of Convolutional Networks that have a name. The most common are:
- (...)
- VGGNet. The runner-up in ILSVRC 2014 was the network from Karen Simonyan and Andrew Zisserman that became known as the VGGNet. Its main contribution was in showing that the depth of the network is a critical component for good performance. Their final best network contains 16 CONV/FC layers and, appealingly, features an extremely homogeneous architecture that only performs 3x3 convolutions and 2x2 pooling from the beginning to the end. Their pretrained model is available for plug and play use in Caffe. A downside of the VGGNet is that it is more expensive to evaluate and uses a lot more memory and parameters (140M). Most of these parameters are in the first fully connected layer, and it was since found that these FC layers can be removed with no performance downgrade, significantly reducing the number of necessary parameters.
- QUOTE: There are several architectures in the field of Convolutional Networks that have a name. The most common are:
2017
- (Li, Johnson & Yeung, 2017) ⇒ Fei-Fei Li, Justin Johnson, and Serena Yeung (2017). Lecture 9: CNN Architectures

2016
- (Vedaldi, Lenc, & Henriques, 2016) ⇒ Andrea Vedaldi, Karel Lenc, and Joao Henriques (2016). VGG CNN Practical: Image Regression
- QUOTE: This is an Oxford Visual Geometry Group computer vision practical (Release 2016a).

- QUOTE: This is an Oxford Visual Geometry Group computer vision practical (Release 2016a).
2014
- (Simonyan & Zisserman, 2014) ⇒ Karen Simonyan, and Andrew Zisserman (2014). "Very deep convolutional networks for large-scale image recognition". arXiv preprint arXiv:1409.1556.
- QUOTE: As can be seen from Table 7, our very deep ConvNets significantly outperform the previous generation of models, which achieved the best results in the ILSVRC-2012 and ILSVRC-2013 competitions. Our result is also competitive with respect to the classification task winner (GoogLeNet with 6.7% error) and substantially outperforms the ILSVRC-2013 winning submission Clarifai, which achieved 11.2% with outside training data and 11.7% without it. This is remarkable, considering that our best result is achieved by combining just two models – significantly less than used in most ILSVRC submissions. In terms of the single-net performance, our architecture achieves the best result (7.0% test error), outperforming a single GoogLeNet by 0.9%. Notably, we did not depart from the classical ConvNet architecture of LeCun et al. (1989), but improved it by substantially increasing the depth.