Retrieval Augmented Generation (RAG)-based System
(Redirected from RAG application)
Jump to navigation
Jump to search
A Retrieval Augmented Generation (RAG)-based System is an LLM-based system that implements a RAG technique to solve RAG-based tasks (by incorporating external knowledge through information retrieval supporting natural language generation tasks).
- AKA: RAG System, Retrieval-Enhanced Generation System, RAG-based System, Retrieval-Augmented Natural Language Generation System.
- Context:
- It can (typically) implement Document Indexing Process through document chunking, embedding generation, and vector index creation.
- It can (typically) execute Query Processing through query embedding and relevant document retrieval.
- It can (typically) perform Answer Generation using retrieved content and LLM integration.
- It can (typically) maintain Knowledge Freshness through dynamic knowledge base updates.
- It can (typically) reduce Hallucination by grounding response generation in retrieved documents.
- ...
- It can often support Document Question Answering through passage retrieval and answer synthesis.
- It can often perform Information Synthesis across multiple retrieved passages.
- It can often enable Citation Generation through source tracking of retrieved content.
- It can often implement Recursive Retrieval for complex query resolution.
- ...
- It can range from being a Basic RAG System to being an Advanced RAG System, depending on its retrieval sophistication.
- It can range from being a Single-Stage RAG to being a Multi-Stage RAG, depending on its retrieval-generation pipeline.
- It can range from being an Any-Domain RAG System to being a Domain-Specific RAG System, depending on its domain specificity.
- ...
- It can be composed of RAG system components, such as:
- Vector Store for embedding storage and similarity search
- Embeddings Component for text encoding and semantic representation
- Natural Language Understanding Component for query processing and intent recognition
- Conversational Retrieval Component for document matching and relevance ranking
- Chat History Component for context management and conversation tracking
- LLM Integration Component for response generation and content synthesis
- ...
- It can integrate with Vector Databases for efficient retrieval.
- It can connect to Document Stores for knowledge management.
- It can support Knowledge Graphs for structured information retrieval.
- ...
- Examples:
- Application-Specific RAG Systems, such as:
- Customer Support RAG Systems, such as:
- Educational RAG Systems, such as:
- Legal RAG Systems, such as:
- Research RAG Systems, such as:
- Architecture-Specific RAG Systems, such as:
- ...
- Application-Specific RAG Systems, such as:
- Counter-Examples:
- Standard Language Models, which lack external knowledge retrieval.
- Document Search Systems, which lack generative capabilities.
- Knowledge Base Systems, which lack dynamic text generation.
- Rule-Based Chatbots, which lack knowledge integration.
- See: RAG Technique, Language Model, Information Retrieval System, Vector Database, Question Answering System, Knowledge Base System.
References
2024b
- (Barnett et al., 2024) ⇒ Scott Barnett, Stefanus Kurniawan, Srikanth Thudumu, Zach Brannelly, and Mohamed Abdelrazek. (2024). “Seven Failure Points When Engineering a Retrieval Augmented Generation System.” doi:10.48550/arXiv.2401.05856
- NOTES:
- RAG-based Systems involve two key processes: document indexing and query processing. Document indexing includes document chunking, embedding generation, and vector index creation. Query processing involves query embedding, relevant document retrieval, and answer generation using the retrieved documents and an LLM.
- The effectiveness of a RAG-based System depends on several factors, including the quality and relevance of the indexed documents, the performance of the retrieval system, and the ability of the LLM to generate accurate and coherent answers using the retrieved content.
- Testing and monitoring RAG-based Systems can be challenging due to their reliance on LLMs and the difficulty in predicting all possible user queries. Continuous system calibration and monitoring during operation are crucial for ensuring the system's robustness and reliability.
- Potential areas for further research on RAG-based Systems include exploring different document chunking and embedding strategies, comparing the performance of RAG approaches with finetuning methods, and developing best practices for software engineering and testing of these systems.
- NOTES:
2024a
- (Gao et al., 2024) ⇒ Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang, and Haofen Wang. (2024). “Retrieval-Augmented Generation for Large Language Models: A Survey.” doi:10.48550/arXiv.2312.10997
2023
- https://medium.com/@abdullahw72/langchain-chatbot-for-multiple-pdfs-harnessing-gpt-and-free-huggingface-llm-alternatives-9a106c239975
- QUOTE:
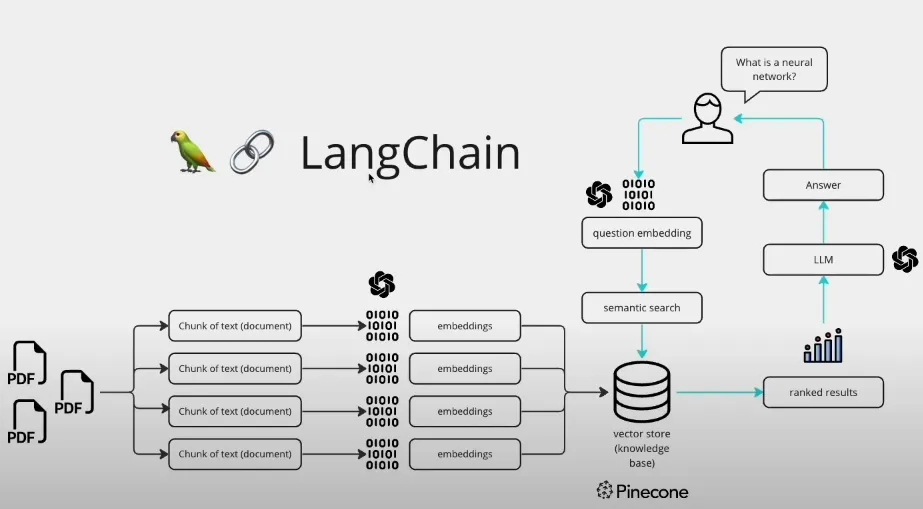
- SUMMARY:
- Architecture
- User Interface: Allows users to input questions and view responses.
- Natural Language Understanding (NLU): Understands and interprets user queries. Uses NLP techniques like tokenization and named entity recognition.
- Vector Store: Stores vector representations of text chunks extracted from PDFs. Generated using embeddings.
- Embeddings: Encode semantic information from text chunks into vectors. Can use OpenAI or Hugging Face models.
- Large Language Models (LLMs): Provide advanced language capabilities. Fine-tuned models like those from OpenAI or Hugging Face's Instruct series.
- Conversational Retrieval: Matches user query vectors to document vector representations to find relevant information.
- Chat History: Stores conversation context to enable coherent, relevant responses.
- Implementation
- Uses Python lang with Streamlit, PyPDF2, Langchain and other libraries.
- Key steps: Extract PDF text, split into chunks, generate embeddings, create vector store, set up conversation chain and chat model, process user input.
- Supports OpenAI and Hugging Face models for text embedding system and LLMs.
- QUOTE: