Automated Visual Entity Recognition Task
(Redirected from Image Recognition Task)
Jump to navigation
Jump to search
A Automated Visual Entity Recognition Task is an image processing task that is a recognition task whose label set is an image pattern, such as an object type, specific object, feature, or activity.
- Context:
- Input: an Image Item.
- Output: Segmented Images.
- It can be supported by a Visual Entity Detection Task.
- It can range from being a Small-Scale Visual Recognition Task to being a Large-Scale Visual Recognition Task.
- It can be solved by a Visual Recognition System that applies a Visual Recognition Algorithm.
- It can be composed of a Visual Entity Segmentation Task and a Visual Entity Classification Task.
- It can range from being a Heuristic Visual Recognition to being a Data-Driven Visual Recognition Task such as Supervised Visual Recognition.
- ...
- Example(s):
- Visual Text Recognition, such as: optical character Recognition.
- Facial Recognition, such as: human face recognition.
- Large-Scale Visual Recognition Datasets, such as:
- Content Moderation, such as: Nude Image Recognition
- Traffic Sign Recognition, such as: Stop Sign Image Recognition
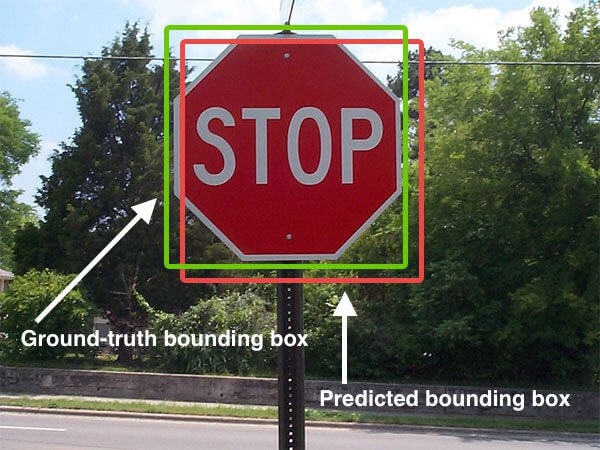
- ...
- Counter-Example(s):
- See: Pattern Recognition, Vision Task, Image Restoration, Digital Image Processing, Video Tracking, People Counter, Object Recognition, MNIST Database, Object Detection, Content-Based Image Retrieval, Pose (Computer Vision), Assembly Line.
References
2024
- Perplexity
- Visual entity recognition is the task of identifying and classifying specific objects, people, activities, or other visual entities present in an image or video.
- Some key points about visual entity recognition:
- The input is an image or video frame.[1][2]
- The goal is to locate and label the various visual entities or concepts within the visual data, such as objects (e.g. car, chair), people, animals, actions, scenes, etc.[1][3]
- It involves both detecting the presence of entities and classifying them into predefined categories.[1][3]
- It can target a wide range of entity types and granularities, from coarse categories like vehicles to fine-grained classes like specific car models.[3]
- Modern approaches use deep learning techniques like convolutional neural networks trained on large datasets.[1][3]
- Major benchmarks include the ImageNet challenge for object classification/detection and the newer Open-domain Visual Entity Recognition (OVEN) task that aims to recognize millions of Wikipedia entities.[1][3]
- It differs from named entity recognition (NER) which deals with identifying named entities like people, organizations, locations in text data rather than visual data.[4][5]
- The example stop sign image[2] illustrates a simple visual entity recognition task of detecting and classifying the stop sign object in the image. The OVEN-Wiki dataset[3] represents a large-scale effort to unify and evaluate visual recognition across a wide variety of visual entities grounded to Wikipedia concepts.
- Citations:
[1] https://en.wikipedia.org/wiki/Computer_vision [2] http://www.pyimagesearch.com/wp-content/uploads/2016/09/iou_stop_sign.jpg [3] https://openaccess.thecvf.com/content/ICCV2023/papers/Hu_Open-domain_Visual_Entity_Recognition_Towards_Recognizing_Millions_of_Wikipedia_Entities_ICCV_2023_paper.pdf [4] https://arxiv.org/abs/2403.02041 [5] https://www.geeksforgeeks.org/named-entity-recognition/
2024
- (Wikipedia, 2024) ⇒ [Computer Vision: Recognition](https://en.wikipedia.org/wiki/Computer_vision#Recognition) Retrieved: 2024-5-19.
- Computer vision tasks include methods for acquiring, processing, analyzing and understanding digital images, and extraction of high-dimensional data from the real world in order to produce numerical or symbolic information, e.g. in the forms of decisions. Understanding in this context means the transformation of visual images (the input to the retina in the human analog) into descriptions of the world that make sense to thought processes and can elicit appropriate action. This image understanding can be seen as the disentangling of symbolic information from image data using models constructed with the aid of geometry, physics, statistics, and learning theory.
- The scientific discipline of computer vision is concerned with the theory behind artificial systems that extract information from images. The image data can take many forms, such as video sequences, views from multiple cameras, multi-dimensional data from a 3D scanner, 3D point clouds from LiDAR sensors, or medical scanning devices. The technological discipline of computer vision seeks to apply its theories and models to the construction of computer vision systems.
- Sub-domains of computer vision include scene reconstruction, object detection, event detection, activity recognition, video tracking, object recognition, 3D pose estimation, learning, indexing, motion estimation, visual servoing, 3D scene modeling, and image restoration.
- Adopting computer vision technology might be painstaking for organizations as there is no single-point solution for it. Very few companies provide a unified and distributed platform or Operating System where computer vision applications can be easily deployed and managed.
2018
- (Wikipedia, 2018) ⇒ [Computer Vision: Recognition](https://en.wikipedia.org/wiki/Computer_vision#Recognition) Retrieved: 2018-5-23.
- The classical problem in computer vision, image processing, and machine vision is determining whether or not the image data contains some specific object, feature, or activity. Different varieties of the recognition problem are described in the literature:
- Object Recognition (also called object classification)—one or several pre-specified or learned objects or object classes can be recognized, usually together with their 2D positions in the image or 3D poses in the scene.
- Identification—an individual instance of an object is recognized. Examples include identification of a specific person's face or fingerprint, identification of handwritten digits, or identification of a specific vehicle.
- Detection—the image data are scanned for a specific condition. Examples include detection of possible abnormal cells or tissues in medical images or detection of a vehicle in an automatic road toll system. Detection based on relatively simple and fast computations is sometimes used for finding smaller regions of interesting image data which can be further analyzed by more computationally demanding techniques to produce a correct interpretation.
- Currently, the best algorithms for such tasks are based on convolutional neural networks. An illustration of their capabilities is given by the ImageNet Large Scale Visual Recognition Challenge; this is a benchmark in object classification and detection, with millions of images and hundreds of object classes. Performance of convolutional neural networks on the ImageNet tests is now close to that of humans.
- Several specialized tasks based on recognition exist, such as:
- Content-Based Image Retrieval—finding all images in a larger set of images that have a specific content. The content can be specified in different ways, for example in terms of similarity relative to a target image (give me all images similar to image X), or in terms of high-level search criteria given as text input (give me all images which contain many houses, are taken during winter, and have no cars in them).
- Pose Estimation—estimating the position or orientation of a specific object relative to the camera. An example application for this technique would be assisting a robot arm in retrieving objects from a conveyor belt in an Assembly Line situation or picking parts from a bin.
- Optical Character Recognition (OCR)—identifying characters in images of printed or handwritten text, usually with a view to encoding the text in a format more amenable to editing or indexing (e.g., ASCII).
- 2D Code Reading—reading of 2D codes such as data matrix and QR codes.
- Facial Recognition
- Shape Recognition Technology (SRT) in People Counter systems differentiating human beings (head and shoulder patterns) from objects.
- The classical problem in computer vision, image processing, and machine vision is determining whether or not the image data contains some specific object, feature, or activity. Different varieties of the recognition problem are described in the literature:
2016
- [Intersection over Union (IoU) for Object Detection](http://www.pyimagesearch.com/2016/11/07/intersection-over-union-iou-for-object-detection/)
- QUOTE:
- QUOTE:
1962
- (Hu, 1962) ⇒ Ming-Kuei Hu. (1962). “Visual pattern recognition by moment invariants.” In: IRE Transactions on Information Theory, 8(2).